 合作(zuò)
合作(zuò)

 咨詢
咨詢

 建站(zhàn)咨詢
建站(zhàn)咨詢

了解入門(mén)爬蟲技(jì)術(shù)原理(lǐ),看這篇就夠了
- 作(zuò)者:admin
- 發表時(shí)間(jiān):2018-04-18 09:22:35
- 來(lái)源:未知
注:爬蟲技(jì)術(shù)就是一個(gè)高(gāo)效的下載系統,能夠将海量的網頁數(shù)據傳送到本地,在本地形成互聯網網頁的鏡像備份。本文從爬蟲技(jì)術(shù)的誕生(shēng)開(kāi)始,為(wèi)你(nǐ)詳細解析爬蟲技(jì)術(shù)原理(lǐ)。
文/Kevin

一、爬蟲系統的誕生(shēng)
通(tōng)用搜索引擎的處理(lǐ)對象是互聯網網頁,目前互聯網網頁的數(shù)量已達百億,所以搜索引擎首先面臨的問題是:如何能夠設計(jì)出高(gāo)效的下載系統,以将如此海量的網頁數(shù)據傳送到本地,在本地形成互聯網網頁的鏡像備份。
網絡爬蟲能夠起到這樣的作(zuò)用,完成此項艱巨的任務,它是搜索引擎系統中很(hěn)關鍵也很(hěn)基礎的構件。
本文主要介紹與網絡爬蟲相關的技(jì)術(shù),盡管爬蟲經過幾十年的發展,從整體(tǐ)框架上(shàng)來(lái)看已經相對成熟,但(dàn)随着互聯網的不斷發展,也面臨着一些(xiē)新的挑戰。
二、通(tōng)用爬蟲技(jì)術(shù)框架
爬蟲系統首先從互聯網頁面中精心選擇一部分網頁,以這些(xiē)網頁的鏈接地址作(zuò)為(wèi)種子URL,将這些(xiē)種子放入待抓取URL隊列中,爬蟲從待抓取URL隊列依次讀取,并将URL通(tōng)過DNS解析,把鏈接地址轉換為(wèi)網站(zhàn)服務器(qì)對應的IP地址。
然後将其和(hé)網頁相對路徑名稱交給網頁下載器(qì),網頁下載器(qì)負責頁面的下載。
對于下載到本地的網頁,一方面将其存儲到頁面庫中,等待建立索引等後續處理(lǐ);另一方面将下載網頁的URL放入已抓取隊列中,這個(gè)隊列記錄了爬蟲系統已經下載過的網頁URL,以避免系統的重複抓取。
對于剛下載的網頁,從中抽取出包含的所有(yǒu)鏈接信息,并在已下載的URL隊列中進行(xíng)檢查,如果發現鏈接還(hái)沒有(yǒu)被抓取過,則放到待抓取URL隊列的末尾。在之後的抓取調度中會(huì)下載這個(gè)URL對應的網頁。
如此這般,形成循環,直到待抓取URL隊列為(wèi)空(kōng),這代表着爬蟲系統将能夠抓取的網頁已經悉數(shù)抓完,此時(shí)完成了一輪完整的抓取過程。
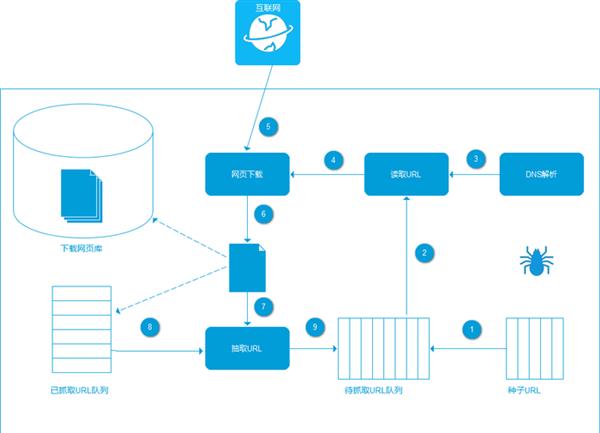
通(tōng)用爬蟲架構
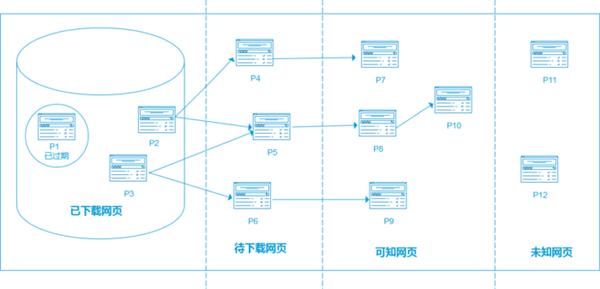
上(shàng)述是一個(gè)通(tōng)用爬蟲的整體(tǐ)流程,如果從更加宏觀的角度考慮,處于動态抓取過程中的爬蟲和(hé)互聯網所有(yǒu)網頁之間(jiān)的關系,可(kě)以概括為(wèi)以下 5 個(gè)部分:
已下載網頁結合:爬蟲已經從互聯網下載到本地進行(xíng)索引的網頁集合。
已過期網頁結合:由于網頁數(shù)量龐大(dà),爬蟲完整抓取一輪需要較長時(shí)間(jiān),在抓取過程中,很(hěn)多(duō)已下載的網頁可(kě)能已經更新了,從而導緻過期。之所以如此,是因為(wèi)互聯網網頁處于不斷的動态變化過程中,所以易産生(shēng)本地網頁內(nèi)容和(hé)真實互聯網不一緻的情況。
待下載網頁集合:處于待抓取URL隊列中的網頁,這些(xiē)網頁即将被爬蟲下載。
可(kě)知網頁集合:這些(xiē)網頁還(hái)沒有(yǒu)被爬蟲下載,也沒有(yǒu)出現在待抓取URL隊列中,通(tōng)過已經抓取的網頁或者在待抓取URL隊列中的網頁,總是能夠通(tōng)過鏈接關系發現它們,稍晚時(shí)候會(huì)被爬蟲抓取并索引。
未知網頁集合:有(yǒu)些(xiē)網頁對于爬蟲是無法抓取到的,這部分網頁構成了未知網頁結合。事實上(shàng),這部分網頁所占的比例很(hěn)高(gāo)。
互聯網頁面劃分
從理(lǐ)解爬蟲的角度看,對互聯網網頁給出如上(shàng)劃分有(yǒu)助于深入理(lǐ)解搜索引擎爬蟲所面臨的主要任務和(hé)挑戰。絕大(dà)多(duō)數(shù)爬蟲系統遵循上(shàng)文的流程,但(dàn)是并非所有(yǒu)的爬蟲系統都如此一緻。根據具體(tǐ)應用的不同,爬蟲系統在許多(duō)方面存在差異,大(dà)體(tǐ)而已,可(kě)以将爬蟲系統分為(wèi)如下 3 種類型:
1.批量型爬蟲:批量型爬蟲有(yǒu)比較明(míng)确的抓取範圍和(hé)目标,當爬蟲達到這個(gè)設定的目标後,即停止抓取過程。
至于具體(tǐ)目标可(kě)能各異,也許是設定抓取一定數(shù)量的網頁即可(kě),也許是設定抓取的時(shí)間(jiān)等,各不一樣。
2.增量型爬蟲:增量型爬蟲與批量型爬蟲不同,會(huì)保持持續不斷的抓取,對于抓取到的網頁,要定期更新。
因為(wèi)互聯網網頁處于不斷變化中,新增網頁、網頁被删除或者網頁內(nèi)容更改都很(hěn)常見,而增量型爬蟲需要及時(shí)反映這種變化,所以處于持續不斷的抓取過程中,不是在抓取新網頁,就是在更新已有(yǒu)網頁。通(tōng)用的商業搜索引擎爬蟲基本都屬此類。
3.垂直型爬蟲:垂直型爬蟲關注特定主題內(nèi)容或者屬于特定行(xíng)業的網頁,比如對于健康網站(zhàn)來(lái)說,隻需要從互聯網頁面裏找到與健康相關的頁面內(nèi)容即可(kě),其他行(xíng)業的內(nèi)容不在考慮範圍。
垂直型爬蟲一個(gè)最大(dà)的特點和(hé)難點就是:如何識别網頁內(nèi)容是否屬于指定行(xíng)業或主題。
從節省系統資源的角度來(lái)講,不可(kě)能把所有(yǒu)互聯網頁面下載之後在進行(xíng)篩選,這樣會(huì)造成資源過度浪費,往往需要爬蟲在抓取階段就能夠動态識别某個(gè)網址是否與主題相關,并盡量不去抓取無關頁面,以達到節省資源的目的。垂直搜索網站(zhàn)或者垂直行(xíng)業網站(zhàn)往往需要此種類型的爬蟲。
三、優秀爬蟲的特性
優秀爬蟲的特性對于不同的應用來(lái)說,可(kě)能實現的方式各有(yǒu)差異,但(dàn)是實用的爬蟲都應該具備以下特性:
1.高(gāo)性能
互聯網的網頁數(shù)量是海量的,所以爬蟲的性能至關重要。這裏的性能主要是指爬蟲下載網頁的抓取速度,常見的評價方式是以爬蟲每秒(miǎo)能夠下載的網頁數(shù)量作(zuò)為(wèi)性能指标,單位時(shí)間(jiān)能夠下載的網頁數(shù)量越多(duō),爬蟲的性能越高(gāo)。
要提高(gāo)爬蟲的性能,在設計(jì)時(shí)程序訪問磁盤的操作(zuò)方法及具體(tǐ)實現時(shí)數(shù)據結構的選擇很(hěn)關鍵,比如對于待抓取URL隊列和(hé)已抓取URL隊列,因為(wèi)URL數(shù)量非常大(dà),不同實現方式性能表現迥異,所以高(gāo)效的數(shù)據結構對于爬蟲性能影(yǐng)響很(hěn)大(dà)。
2.可(kě)擴展性
即使單個(gè)爬蟲的性能很(hěn)高(gāo),要将所有(yǒu)網頁都下載到本地,仍然需要相當長的時(shí)間(jiān)周期,為(wèi)了能夠盡可(kě)能縮短(duǎn)抓取周期,爬蟲系統應該有(yǒu)很(hěn)好地可(kě)擴展性,即很(hěn)容易通(tōng)過增加抓取服務器(qì)和(hé)爬蟲數(shù)量來(lái)達到此目的。
目前實用的大(dà)型網絡爬蟲一定是分布式運行(xíng)的,即多(duō)台服務器(qì)專做(zuò)抓取。每台服務器(qì)部署多(duō)個(gè)爬蟲,每個(gè)爬蟲多(duō)線程運行(xíng),通(tōng)過多(duō)種方式增加并發性。
對于巨型的搜索引擎服務商來(lái)說,可(kě)能還(hái)要在全球範圍、不同地域分别部署數(shù)據中心,爬蟲也被分配到不同的數(shù)據中心,這樣對于提高(gāo)爬蟲系統的整體(tǐ)性能是很(hěn)有(yǒu)幫助的。
3.健壯性
爬蟲要訪問各種類型的網站(zhàn)服務器(qì),可(kě)能會(huì)遇到很(hěn)多(duō)種非正常情況:比如網頁HTML編碼不規範、 被抓取服務器(qì)突然死機,甚至爬蟲陷阱等。爬蟲對各種異常情況能否正确處理(lǐ)非常重要,否則可(kě)能會(huì)不定期停止工作(zuò),這是無法忍受的。
從另外一個(gè)角度來(lái)講,假設爬蟲程序在抓取過程中死掉,或者爬蟲所在的服務器(qì)宕機,健壯的爬蟲應能做(zuò)到:再次啓動爬蟲時(shí),能夠恢複之前抓取的內(nèi)容和(hé)數(shù)據結構,而不是每次都需要把所有(yǒu)工作(zuò)完全從頭做(zuò)起,這也是爬蟲健壯性的一種體(tǐ)現。
4.友(yǒu)好性
爬蟲的友(yǒu)好性包含兩方面的含義:一是保護網站(zhàn)的部分私密性;另一是減少(shǎo)被抓取網站(zhàn)的網絡負載。爬蟲抓取的對象是各類型的網站(zhàn),對于網站(zhàn)所有(yǒu)者來(lái)說,有(yǒu)些(xiē)內(nèi)容并不希望被所有(yǒu)人(rén)搜到,所以需要設定協議,來(lái)告知爬蟲哪些(xiē)內(nèi)容是不允許抓取的。目前有(yǒu)兩種主流的方法可(kě)達到此目的:爬蟲禁抓協議和(hé)網頁禁抓标記。
爬蟲禁抓協議指的是由網站(zhàn)所有(yǒu)者生(shēng)成一個(gè)指定的文件robot.txt,并放在網站(zhàn)服務器(qì)的根目錄下,這個(gè)文件指明(míng)了網站(zhàn)中哪些(xiē)目錄下的網頁是不允許爬蟲抓取的。具有(yǒu)友(yǒu)好性的爬蟲在抓取該網站(zhàn)的網頁前,首先要讀取robot.txt文件,對于禁止抓取的網頁不進行(xíng)下載。
網頁禁抓标記一般在網頁的HTML代碼裏加入meta name=”robots”标記,content字段指出允許或者不允許爬蟲的哪些(xiē)行(xíng)為(wèi)。可(kě)以分為(wèi)兩種情形:一種是告知爬蟲不要索引該網頁內(nèi)容,以noindex作(zuò)為(wèi)标記;另外一種情形是告知爬蟲不要抓取網頁所包含的鏈接,以nofollow作(zuò)為(wèi)标記。通(tōng)過這種方式,可(kě)以達到對網頁內(nèi)容的一種隐私保護。
遵循以上(shàng)協議的爬蟲可(kě)以被認為(wèi)是友(yǒu)好的,這是從保護私密性的角度來(lái)考慮的;另外一種友(yǒu)好性則是,希望爬蟲對某網站(zhàn)的訪問造成的網路負載較低(dī)。
爬蟲一般會(huì)根據網頁的鏈接連續獲取某網站(zhàn)的網頁,如果爬蟲訪問網站(zhàn)頻率過高(gāo),會(huì)給網站(zhàn)服務器(qì)造成很(hěn)大(dà)的訪問壓力,有(yǒu)時(shí)候甚至會(huì)影(yǐng)響網站(zhàn)的正常訪問,造成類似DOS攻擊的效果。
為(wèi)了減少(shǎo)網站(zhàn)的網絡負載,友(yǒu)好性的爬蟲應該在抓取策略部署時(shí)考慮每個(gè)被抓取網站(zhàn)的負載,在盡可(kě)能不影(yǐng)響爬蟲性能的情況下,減少(shǎo)對單一站(zhàn)點短(duǎn)期內(nèi)的高(gāo)頻訪問。
四、爬蟲質量的評價标準
如果從搜索引擎用戶體(tǐ)驗的角度考慮,對爬蟲的工作(zuò)效果有(yǒu)不同的評價标準,其中最主要的 3 個(gè)标準是:抓取網頁的覆蓋率、抓取網頁時(shí)新性及抓取網頁重要性。如果這 3 方面做(zuò)得(de)好,則搜索引擎用戶體(tǐ)驗必定好。
對于現有(yǒu)的搜索引擎來(lái)說,還(hái)不存在哪個(gè)搜索引擎有(yǒu)能力将互聯網上(shàng)出現的所有(yǒu)網頁都下載并建立索引,所有(yǒu)搜索引擎隻能索引互聯網的一部分。而所謂的抓取覆蓋率指的是爬蟲抓取網頁的數(shù)量占互聯網所有(yǒu)網頁數(shù)量的比例,覆蓋率越高(gāo),等價于搜索引擎的召回率越高(gāo),用戶體(tǐ)驗越好。
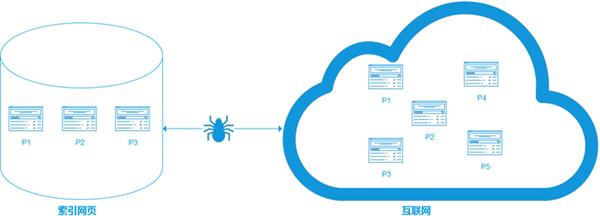
索引網頁和(hé)互聯網網頁對比
抓取到本地的網頁,很(hěn)有(yǒu)可(kě)能已經發生(shēng)變化,或者被删除,或者內(nèi)容被更改,因為(wèi)爬蟲抓取完一輪需要較長的時(shí)間(jiān)周期,所以抓取到的網頁當中必然會(huì)有(yǒu)一部分是過期的數(shù)據,即不能在網頁變化後第一時(shí)間(jiān)反應到網頁庫中。所以網頁庫中過期的數(shù)據越少(shǎo),則網頁的時(shí)新性越好,這對用戶體(tǐ)驗的改善大(dà)有(yǒu)裨益。
如果時(shí)新性不好,搜索到的都是過期數(shù)據,或者網頁被删除,用戶的內(nèi)心感受可(kě)想而知。
互聯網盡管網頁繁多(duō),但(dàn)是每個(gè)網頁的差異性都很(hěn)大(dà),比如來(lái)自騰訊、網易新聞的網頁和(hé)某個(gè)作(zuò)弊網頁相比,其重要性猶如天壤之别。如果搜索引擎抓取到的網頁大(dà)部分是比較重要的網頁,則可(kě)以說明(míng)在抓取網頁重要性方面做(zuò)得(de)比較好。這方面做(zuò)的越好,則越說明(míng)搜索引擎的搜索精度越高(gāo)。
通(tōng)過以上(shàng) 3 個(gè)标準的說明(míng)分析,可(kě)以将爬蟲研發的目标簡單描述如下:在資源有(yǒu)限的情況下,既然搜索引擎隻能抓取互聯網現存網頁的一部分,那(nà)麽就盡可(kě)能給選擇比較重要的那(nà)部分頁面來(lái)索引;對于已經抓取到的網頁,盡可(kě)能快的更新內(nèi)容,使得(de)索引網頁和(hé)互聯網對應頁面內(nèi)容同步更新;在此基礎上(shàng),盡可(kě)能擴大(dà)抓取範圍,抓取到更多(duō)以前無法發現的網頁。
3 個(gè)“盡可(kě)能”基本說清楚了爬蟲系統為(wèi)增強用戶體(tǐ)驗而奮鬥的目标。
大(dà)型商業搜索引擎為(wèi)了滿足 3 個(gè)質量标準,大(dà)都開(kāi)發了多(duō)套針對性很(hěn)強的爬蟲系統。以Google為(wèi)例,至少(shǎo)包含兩套不同的爬蟲系統:一套被稱為(wèi)Fresh Bot,主要考慮網頁的時(shí)新性,對于內(nèi)容更新頻繁的網頁,目前可(kě)以達到以秒(miǎo)計(jì)的更新周期;另外一套被稱之為(wèi)Deep Crawl Bot,主要針對更新不是那(nà)麽頻繁的網頁抓取,以天為(wèi)更新周期。
除此之外,Google投入了很(hěn)大(dà)精力研發針對暗網的抓取系統,後續,有(yǒu)時(shí)間(jiān)再說明(míng)暗網系統。
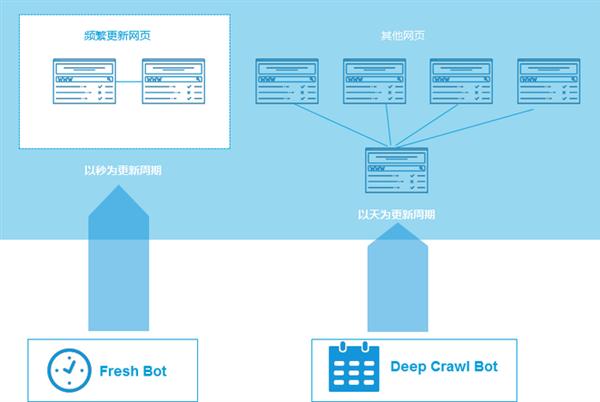
Google的兩套爬蟲系統
五、最後的總結
閱讀本文,通(tōng)過了解爬蟲的技(jì)術(shù)架構、爬蟲的類型、優秀爬蟲的特性、爬蟲質量标準,相信你(nǐ)對爬蟲系統已經有(yǒu)了一個(gè)初步的系統性的認識,最後将主要知識點做(zuò)一個(gè)簡短(duǎn)的綱領性總結:
爬蟲抓取網頁的工作(zuò)流程:選擇待抓取網頁,按順序放入待抓取隊列;系統依次将網頁鏈接地址轉換為(wèi)IP地址,下載到本地後,按順序進行(xíng)存儲和(hé)标記,避免重複下載;繼續執行(xíng)新一輪的抓取,周而複始。
爬蟲和(hé)互聯網所有(yǒu)網頁之間(jiān)的關系:已下載網頁結合、已過期網頁結合、待下載網頁結合、可(kě)知網頁結合、未知網頁結合
爬蟲類型:批量型爬蟲、增量型爬蟲、垂直型爬蟲
優秀爬蟲的特性:高(gāo)性能、可(kě)擴展性、健壯性、友(yǒu)好性
爬蟲質量的評價标準:抓取網頁的覆蓋率、抓取網頁時(shí)新性及抓取網頁重要性
文/Kevin
一、爬蟲系統的誕生(shēng)
通(tōng)用搜索引擎的處理(lǐ)對象是互聯網網頁,目前互聯網網頁的數(shù)量已達百億,所以搜索引擎首先面臨的問題是:如何能夠設計(jì)出高(gāo)效的下載系統,以将如此海量的網頁數(shù)據傳送到本地,在本地形成互聯網網頁的鏡像備份。
網絡爬蟲能夠起到這樣的作(zuò)用,完成此項艱巨的任務,它是搜索引擎系統中很(hěn)關鍵也很(hěn)基礎的構件。
本文主要介紹與網絡爬蟲相關的技(jì)術(shù),盡管爬蟲經過幾十年的發展,從整體(tǐ)框架上(shàng)來(lái)看已經相對成熟,但(dàn)随着互聯網的不斷發展,也面臨着一些(xiē)新的挑戰。
二、通(tōng)用爬蟲技(jì)術(shù)框架
爬蟲系統首先從互聯網頁面中精心選擇一部分網頁,以這些(xiē)網頁的鏈接地址作(zuò)為(wèi)種子URL,将這些(xiē)種子放入待抓取URL隊列中,爬蟲從待抓取URL隊列依次讀取,并将URL通(tōng)過DNS解析,把鏈接地址轉換為(wèi)網站(zhàn)服務器(qì)對應的IP地址。
然後将其和(hé)網頁相對路徑名稱交給網頁下載器(qì),網頁下載器(qì)負責頁面的下載。
對于下載到本地的網頁,一方面将其存儲到頁面庫中,等待建立索引等後續處理(lǐ);另一方面将下載網頁的URL放入已抓取隊列中,這個(gè)隊列記錄了爬蟲系統已經下載過的網頁URL,以避免系統的重複抓取。
對于剛下載的網頁,從中抽取出包含的所有(yǒu)鏈接信息,并在已下載的URL隊列中進行(xíng)檢查,如果發現鏈接還(hái)沒有(yǒu)被抓取過,則放到待抓取URL隊列的末尾。在之後的抓取調度中會(huì)下載這個(gè)URL對應的網頁。
如此這般,形成循環,直到待抓取URL隊列為(wèi)空(kōng),這代表着爬蟲系統将能夠抓取的網頁已經悉數(shù)抓完,此時(shí)完成了一輪完整的抓取過程。
通(tōng)用爬蟲架構
上(shàng)述是一個(gè)通(tōng)用爬蟲的整體(tǐ)流程,如果從更加宏觀的角度考慮,處于動态抓取過程中的爬蟲和(hé)互聯網所有(yǒu)網頁之間(jiān)的關系,可(kě)以概括為(wèi)以下 5 個(gè)部分:
已下載網頁結合:爬蟲已經從互聯網下載到本地進行(xíng)索引的網頁集合。
已過期網頁結合:由于網頁數(shù)量龐大(dà),爬蟲完整抓取一輪需要較長時(shí)間(jiān),在抓取過程中,很(hěn)多(duō)已下載的網頁可(kě)能已經更新了,從而導緻過期。之所以如此,是因為(wèi)互聯網網頁處于不斷的動态變化過程中,所以易産生(shēng)本地網頁內(nèi)容和(hé)真實互聯網不一緻的情況。
待下載網頁集合:處于待抓取URL隊列中的網頁,這些(xiē)網頁即将被爬蟲下載。
可(kě)知網頁集合:這些(xiē)網頁還(hái)沒有(yǒu)被爬蟲下載,也沒有(yǒu)出現在待抓取URL隊列中,通(tōng)過已經抓取的網頁或者在待抓取URL隊列中的網頁,總是能夠通(tōng)過鏈接關系發現它們,稍晚時(shí)候會(huì)被爬蟲抓取并索引。
未知網頁集合:有(yǒu)些(xiē)網頁對于爬蟲是無法抓取到的,這部分網頁構成了未知網頁結合。事實上(shàng),這部分網頁所占的比例很(hěn)高(gāo)。
互聯網頁面劃分
從理(lǐ)解爬蟲的角度看,對互聯網網頁給出如上(shàng)劃分有(yǒu)助于深入理(lǐ)解搜索引擎爬蟲所面臨的主要任務和(hé)挑戰。絕大(dà)多(duō)數(shù)爬蟲系統遵循上(shàng)文的流程,但(dàn)是并非所有(yǒu)的爬蟲系統都如此一緻。根據具體(tǐ)應用的不同,爬蟲系統在許多(duō)方面存在差異,大(dà)體(tǐ)而已,可(kě)以将爬蟲系統分為(wèi)如下 3 種類型:
1.批量型爬蟲:批量型爬蟲有(yǒu)比較明(míng)确的抓取範圍和(hé)目标,當爬蟲達到這個(gè)設定的目标後,即停止抓取過程。
至于具體(tǐ)目标可(kě)能各異,也許是設定抓取一定數(shù)量的網頁即可(kě),也許是設定抓取的時(shí)間(jiān)等,各不一樣。
2.增量型爬蟲:增量型爬蟲與批量型爬蟲不同,會(huì)保持持續不斷的抓取,對于抓取到的網頁,要定期更新。
因為(wèi)互聯網網頁處于不斷變化中,新增網頁、網頁被删除或者網頁內(nèi)容更改都很(hěn)常見,而增量型爬蟲需要及時(shí)反映這種變化,所以處于持續不斷的抓取過程中,不是在抓取新網頁,就是在更新已有(yǒu)網頁。通(tōng)用的商業搜索引擎爬蟲基本都屬此類。
3.垂直型爬蟲:垂直型爬蟲關注特定主題內(nèi)容或者屬于特定行(xíng)業的網頁,比如對于健康網站(zhàn)來(lái)說,隻需要從互聯網頁面裏找到與健康相關的頁面內(nèi)容即可(kě),其他行(xíng)業的內(nèi)容不在考慮範圍。
垂直型爬蟲一個(gè)最大(dà)的特點和(hé)難點就是:如何識别網頁內(nèi)容是否屬于指定行(xíng)業或主題。
從節省系統資源的角度來(lái)講,不可(kě)能把所有(yǒu)互聯網頁面下載之後在進行(xíng)篩選,這樣會(huì)造成資源過度浪費,往往需要爬蟲在抓取階段就能夠動态識别某個(gè)網址是否與主題相關,并盡量不去抓取無關頁面,以達到節省資源的目的。垂直搜索網站(zhàn)或者垂直行(xíng)業網站(zhàn)往往需要此種類型的爬蟲。
三、優秀爬蟲的特性
優秀爬蟲的特性對于不同的應用來(lái)說,可(kě)能實現的方式各有(yǒu)差異,但(dàn)是實用的爬蟲都應該具備以下特性:
1.高(gāo)性能
互聯網的網頁數(shù)量是海量的,所以爬蟲的性能至關重要。這裏的性能主要是指爬蟲下載網頁的抓取速度,常見的評價方式是以爬蟲每秒(miǎo)能夠下載的網頁數(shù)量作(zuò)為(wèi)性能指标,單位時(shí)間(jiān)能夠下載的網頁數(shù)量越多(duō),爬蟲的性能越高(gāo)。
要提高(gāo)爬蟲的性能,在設計(jì)時(shí)程序訪問磁盤的操作(zuò)方法及具體(tǐ)實現時(shí)數(shù)據結構的選擇很(hěn)關鍵,比如對于待抓取URL隊列和(hé)已抓取URL隊列,因為(wèi)URL數(shù)量非常大(dà),不同實現方式性能表現迥異,所以高(gāo)效的數(shù)據結構對于爬蟲性能影(yǐng)響很(hěn)大(dà)。
2.可(kě)擴展性
即使單個(gè)爬蟲的性能很(hěn)高(gāo),要将所有(yǒu)網頁都下載到本地,仍然需要相當長的時(shí)間(jiān)周期,為(wèi)了能夠盡可(kě)能縮短(duǎn)抓取周期,爬蟲系統應該有(yǒu)很(hěn)好地可(kě)擴展性,即很(hěn)容易通(tōng)過增加抓取服務器(qì)和(hé)爬蟲數(shù)量來(lái)達到此目的。
目前實用的大(dà)型網絡爬蟲一定是分布式運行(xíng)的,即多(duō)台服務器(qì)專做(zuò)抓取。每台服務器(qì)部署多(duō)個(gè)爬蟲,每個(gè)爬蟲多(duō)線程運行(xíng),通(tōng)過多(duō)種方式增加并發性。
對于巨型的搜索引擎服務商來(lái)說,可(kě)能還(hái)要在全球範圍、不同地域分别部署數(shù)據中心,爬蟲也被分配到不同的數(shù)據中心,這樣對于提高(gāo)爬蟲系統的整體(tǐ)性能是很(hěn)有(yǒu)幫助的。
3.健壯性
爬蟲要訪問各種類型的網站(zhàn)服務器(qì),可(kě)能會(huì)遇到很(hěn)多(duō)種非正常情況:比如網頁HTML編碼不規範、 被抓取服務器(qì)突然死機,甚至爬蟲陷阱等。爬蟲對各種異常情況能否正确處理(lǐ)非常重要,否則可(kě)能會(huì)不定期停止工作(zuò),這是無法忍受的。
從另外一個(gè)角度來(lái)講,假設爬蟲程序在抓取過程中死掉,或者爬蟲所在的服務器(qì)宕機,健壯的爬蟲應能做(zuò)到:再次啓動爬蟲時(shí),能夠恢複之前抓取的內(nèi)容和(hé)數(shù)據結構,而不是每次都需要把所有(yǒu)工作(zuò)完全從頭做(zuò)起,這也是爬蟲健壯性的一種體(tǐ)現。
4.友(yǒu)好性
爬蟲的友(yǒu)好性包含兩方面的含義:一是保護網站(zhàn)的部分私密性;另一是減少(shǎo)被抓取網站(zhàn)的網絡負載。爬蟲抓取的對象是各類型的網站(zhàn),對于網站(zhàn)所有(yǒu)者來(lái)說,有(yǒu)些(xiē)內(nèi)容并不希望被所有(yǒu)人(rén)搜到,所以需要設定協議,來(lái)告知爬蟲哪些(xiē)內(nèi)容是不允許抓取的。目前有(yǒu)兩種主流的方法可(kě)達到此目的:爬蟲禁抓協議和(hé)網頁禁抓标記。
爬蟲禁抓協議指的是由網站(zhàn)所有(yǒu)者生(shēng)成一個(gè)指定的文件robot.txt,并放在網站(zhàn)服務器(qì)的根目錄下,這個(gè)文件指明(míng)了網站(zhàn)中哪些(xiē)目錄下的網頁是不允許爬蟲抓取的。具有(yǒu)友(yǒu)好性的爬蟲在抓取該網站(zhàn)的網頁前,首先要讀取robot.txt文件,對于禁止抓取的網頁不進行(xíng)下載。
網頁禁抓标記一般在網頁的HTML代碼裏加入meta name=”robots”标記,content字段指出允許或者不允許爬蟲的哪些(xiē)行(xíng)為(wèi)。可(kě)以分為(wèi)兩種情形:一種是告知爬蟲不要索引該網頁內(nèi)容,以noindex作(zuò)為(wèi)标記;另外一種情形是告知爬蟲不要抓取網頁所包含的鏈接,以nofollow作(zuò)為(wèi)标記。通(tōng)過這種方式,可(kě)以達到對網頁內(nèi)容的一種隐私保護。
遵循以上(shàng)協議的爬蟲可(kě)以被認為(wèi)是友(yǒu)好的,這是從保護私密性的角度來(lái)考慮的;另外一種友(yǒu)好性則是,希望爬蟲對某網站(zhàn)的訪問造成的網路負載較低(dī)。
爬蟲一般會(huì)根據網頁的鏈接連續獲取某網站(zhàn)的網頁,如果爬蟲訪問網站(zhàn)頻率過高(gāo),會(huì)給網站(zhàn)服務器(qì)造成很(hěn)大(dà)的訪問壓力,有(yǒu)時(shí)候甚至會(huì)影(yǐng)響網站(zhàn)的正常訪問,造成類似DOS攻擊的效果。
為(wèi)了減少(shǎo)網站(zhàn)的網絡負載,友(yǒu)好性的爬蟲應該在抓取策略部署時(shí)考慮每個(gè)被抓取網站(zhàn)的負載,在盡可(kě)能不影(yǐng)響爬蟲性能的情況下,減少(shǎo)對單一站(zhàn)點短(duǎn)期內(nèi)的高(gāo)頻訪問。
四、爬蟲質量的評價标準
如果從搜索引擎用戶體(tǐ)驗的角度考慮,對爬蟲的工作(zuò)效果有(yǒu)不同的評價标準,其中最主要的 3 個(gè)标準是:抓取網頁的覆蓋率、抓取網頁時(shí)新性及抓取網頁重要性。如果這 3 方面做(zuò)得(de)好,則搜索引擎用戶體(tǐ)驗必定好。
對于現有(yǒu)的搜索引擎來(lái)說,還(hái)不存在哪個(gè)搜索引擎有(yǒu)能力将互聯網上(shàng)出現的所有(yǒu)網頁都下載并建立索引,所有(yǒu)搜索引擎隻能索引互聯網的一部分。而所謂的抓取覆蓋率指的是爬蟲抓取網頁的數(shù)量占互聯網所有(yǒu)網頁數(shù)量的比例,覆蓋率越高(gāo),等價于搜索引擎的召回率越高(gāo),用戶體(tǐ)驗越好。
索引網頁和(hé)互聯網網頁對比
抓取到本地的網頁,很(hěn)有(yǒu)可(kě)能已經發生(shēng)變化,或者被删除,或者內(nèi)容被更改,因為(wèi)爬蟲抓取完一輪需要較長的時(shí)間(jiān)周期,所以抓取到的網頁當中必然會(huì)有(yǒu)一部分是過期的數(shù)據,即不能在網頁變化後第一時(shí)間(jiān)反應到網頁庫中。所以網頁庫中過期的數(shù)據越少(shǎo),則網頁的時(shí)新性越好,這對用戶體(tǐ)驗的改善大(dà)有(yǒu)裨益。
如果時(shí)新性不好,搜索到的都是過期數(shù)據,或者網頁被删除,用戶的內(nèi)心感受可(kě)想而知。
互聯網盡管網頁繁多(duō),但(dàn)是每個(gè)網頁的差異性都很(hěn)大(dà),比如來(lái)自騰訊、網易新聞的網頁和(hé)某個(gè)作(zuò)弊網頁相比,其重要性猶如天壤之别。如果搜索引擎抓取到的網頁大(dà)部分是比較重要的網頁,則可(kě)以說明(míng)在抓取網頁重要性方面做(zuò)得(de)比較好。這方面做(zuò)的越好,則越說明(míng)搜索引擎的搜索精度越高(gāo)。
通(tōng)過以上(shàng) 3 個(gè)标準的說明(míng)分析,可(kě)以将爬蟲研發的目标簡單描述如下:在資源有(yǒu)限的情況下,既然搜索引擎隻能抓取互聯網現存網頁的一部分,那(nà)麽就盡可(kě)能給選擇比較重要的那(nà)部分頁面來(lái)索引;對于已經抓取到的網頁,盡可(kě)能快的更新內(nèi)容,使得(de)索引網頁和(hé)互聯網對應頁面內(nèi)容同步更新;在此基礎上(shàng),盡可(kě)能擴大(dà)抓取範圍,抓取到更多(duō)以前無法發現的網頁。
3 個(gè)“盡可(kě)能”基本說清楚了爬蟲系統為(wèi)增強用戶體(tǐ)驗而奮鬥的目标。
大(dà)型商業搜索引擎為(wèi)了滿足 3 個(gè)質量标準,大(dà)都開(kāi)發了多(duō)套針對性很(hěn)強的爬蟲系統。以Google為(wèi)例,至少(shǎo)包含兩套不同的爬蟲系統:一套被稱為(wèi)Fresh Bot,主要考慮網頁的時(shí)新性,對于內(nèi)容更新頻繁的網頁,目前可(kě)以達到以秒(miǎo)計(jì)的更新周期;另外一套被稱之為(wèi)Deep Crawl Bot,主要針對更新不是那(nà)麽頻繁的網頁抓取,以天為(wèi)更新周期。
除此之外,Google投入了很(hěn)大(dà)精力研發針對暗網的抓取系統,後續,有(yǒu)時(shí)間(jiān)再說明(míng)暗網系統。
Google的兩套爬蟲系統
五、最後的總結
閱讀本文,通(tōng)過了解爬蟲的技(jì)術(shù)架構、爬蟲的類型、優秀爬蟲的特性、爬蟲質量标準,相信你(nǐ)對爬蟲系統已經有(yǒu)了一個(gè)初步的系統性的認識,最後将主要知識點做(zuò)一個(gè)簡短(duǎn)的綱領性總結:
爬蟲抓取網頁的工作(zuò)流程:選擇待抓取網頁,按順序放入待抓取隊列;系統依次将網頁鏈接地址轉換為(wèi)IP地址,下載到本地後,按順序進行(xíng)存儲和(hé)标記,避免重複下載;繼續執行(xíng)新一輪的抓取,周而複始。
爬蟲和(hé)互聯網所有(yǒu)網頁之間(jiān)的關系:已下載網頁結合、已過期網頁結合、待下載網頁結合、可(kě)知網頁結合、未知網頁結合
爬蟲類型:批量型爬蟲、增量型爬蟲、垂直型爬蟲
優秀爬蟲的特性:高(gāo)性能、可(kě)擴展性、健壯性、友(yǒu)好性
爬蟲質量的評價标準:抓取網頁的覆蓋率、抓取網頁時(shí)新性及抓取網頁重要性
聯系我們
一切良好工作(zuò)的開(kāi)始,都需相互之間(jiān)的溝通(tōng)搭橋,歡迎咨詢。



