 合作(zuò)
合作(zuò)

 咨詢
咨詢

 建站(zhàn)咨詢
建站(zhàn)咨詢

百億級日志(zhì)系統架構設計(jì)及優化
- 作(zuò)者:admin
- 發表時(shí)間(jiān):2018-05-24 09:59:30
- 來(lái)源:未知
日志(zhì)數(shù)據是最常見的一種海量數(shù)據,以擁有(yǒu)大(dà)量用戶群體(tǐ)的電(diàn)商平台為(wèi)例,雙 11 大(dà)促活動期間(jiān),它們可(kě)能每小(xiǎo)時(shí)的日志(zhì)數(shù)量達到百億規模,海量的日志(zhì)數(shù)據暴增,随之給技(jì)術(shù)團隊帶來(lái)嚴峻的挑戰。

本文将從海量日志(zhì)系統在優化、部署、監控方向如何更适應業務的需求入手,重點從多(duō)種日志(zhì)系統的架構設計(jì)對比;後續調優過程:橫向擴展與縱向擴展,分集群,數(shù)據分治,重寫數(shù)據鏈路等實際現象與問題展開(kāi)。
日志(zhì)系統架構基準
有(yǒu)過項目開(kāi)發經驗的朋友(yǒu)都知道(dào):從平台的最初搭建到實現核心業務,都需要有(yǒu)日志(zhì)平台為(wèi)各種業務保駕護航。
 如上(shàng)圖所示,對于一個(gè)簡單的日志(zhì)應用場(chǎng)景,通(tōng)常會(huì)準備 master/slave 兩個(gè)應用。我們隻需運行(xíng)一個(gè) Shell 腳本,便可(kě)查看是否存在錯誤信息。
如上(shàng)圖所示,對于一個(gè)簡單的日志(zhì)應用場(chǎng)景,通(tōng)常會(huì)準備 master/slave 兩個(gè)應用。我們隻需運行(xíng)一個(gè) Shell 腳本,便可(kě)查看是否存在錯誤信息。
随着業務複雜度的增加,應用場(chǎng)景也會(huì)變得(de)複雜。雖然監控系統能夠顯示某台機器(qì)或者某個(gè)應用的錯誤。
然而在實際的生(shēng)産環境中,由于實施了隔離,一旦在上(shàng)圖下側的紅框內(nèi)某個(gè)應用出現了 Bug,則無法訪問到其對應的日志(zhì),也就談不上(shàng)将日志(zhì)取出了。
另外,有(yǒu)些(xiē)深度依賴日志(zhì)平台的應用,也可(kě)能在日志(zhì)産生(shēng)的時(shí)候就直接采集走,進而删除掉原始的日志(zhì)文件。這些(xiē)場(chǎng)景給我們日志(zhì)系統的維護都帶來(lái)了難度。
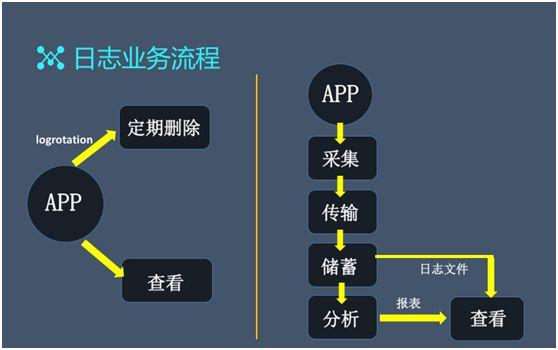
參考 Logstash,一般會(huì)有(yǒu)兩種日志(zhì)業務流程:
正常情況下的簡單流程為(wèi):應用産生(shēng)日志(zhì)→根據預定義的日志(zhì)文件大(dà)小(xiǎo)或時(shí)間(jiān)間(jiān)隔,通(tōng)過執行(xíng) Logrotation,不斷刷新出新的文件→定期查看→定期删除。
複雜應用場(chǎng)景的流程為(wèi):應用産生(shēng)日志(zhì)→采集→傳輸→按需過濾與轉換→存儲→分析與查看。
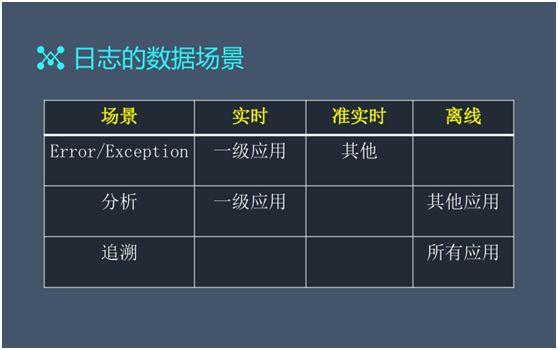
我們可(kě)以從實時(shí)性和(hé)錯誤分析兩個(gè)維度來(lái)區(qū)分不同的日志(zhì)數(shù)據場(chǎng)景:
實時(shí),一般适用于我們常說的一級應用,如:直接面向用戶的應用。我們可(kě)以自定義各類關鍵字,以方便在出現各種 error 或 exception 時(shí),相關業務人(rén)員能夠在第一時(shí)間(jiān)被通(tōng)知到。
準實時(shí),一般适用于一些(xiē)項目管理(lǐ)的平台,如:在需要填寫工時(shí)的時(shí)候出現了宕機,但(dàn)這并不影(yǐng)響工資的發放。
平台在幾分鍾後完成重啓,我們可(kě)以再登錄填寫,該情況并不造成原則性的影(yǐng)響。因此,我們可(kě)以将其列為(wèi)準實時(shí)的級别。
除了直接采集錯誤與異常,我們還(hái)需要進行(xíng)分析。例如:僅知道(dào)某人(rén)的體(tǐ)重是沒什麽意義的,但(dàn)是如果增加了性别和(hé)身高(gāo)兩個(gè)指标,那(nà)麽我們就可(kě)以判斷出此人(rén)的體(tǐ)重是否為(wèi)标準體(tǐ)重。
也就是說:如果能給出多(duō)個(gè)指标,就可(kě)以對龐大(dà)的數(shù)據進行(xíng)去噪,然後通(tōng)過回歸分析,讓采集到的數(shù)據更有(yǒu)意義。
此外,我們還(hái)要不斷地去還(hái)原數(shù)字的真實性。特别是對于實時(shí)的一級應用,我們要能快速地讓用戶明(míng)白他們所碰到現象的真實含義。
例如:商家(jiā)在上(shàng)架時(shí)錯把商品的價格标簽 100 元标成了 10 元。這會(huì)導緻商品馬上(shàng)被搶購一空(kōng)。
但(dàn)是這種現象并非是業務的問題,很(hěn)難被發現,因此我們隻能通(tōng)過日志(zhì)數(shù)據進行(xíng)邏輯分析,及時(shí)反饋以保證在幾十秒(miǎo)之後将庫存修改為(wèi)零,從而有(yǒu)效地解決此問題。可(kě)見,在此應用場(chǎng)景中,實時(shí)分析就顯得(de)非常有(yǒu)用。
最後是追溯,我們需要在獲取曆史信息的同時(shí),實現跨時(shí)間(jiān)維度的對比與總結,那(nà)麽追溯就能夠在各種應用中發揮其關聯性作(zuò)用了。
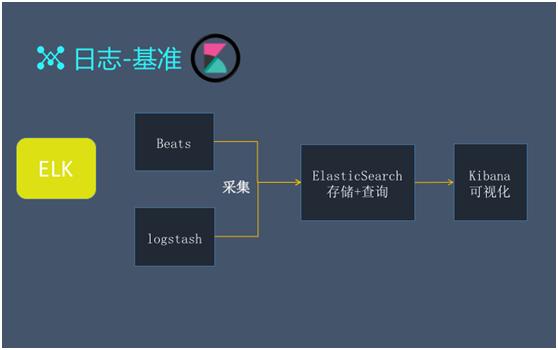
上(shàng)述提及的各個(gè)要素都是我們管理(lǐ)日志(zhì)的基準。如上(shàng)圖所示,我們的日志(zhì)系統采用的是開(kāi)源的 ELK 模式:
ElasticSearch(後簡稱 ES),負責後端集中存儲與查詢工作(zuò)。
單獨的 Beats 負責日志(zhì)的搜集。FileBeat 則改進了 Logstash 的資源占用問題;TopBeat 負責搜集監控資源,類似系統命令 top 去獲取 CPU 的性能。
由于日志(zhì)服務對于業務來(lái)說僅起到了維穩和(hé)保障的作(zuò)用,而且我們需要實現快速、輕量的數(shù)據采集與傳輸,因此不應占用服務器(qì)太多(duō)資源。
在方式上(shàng)我們采用的是插件模式,包括:input 插件、output 插件、以及中間(jiān)負責傳輸過濾的插件。這些(xiē)插件有(yǒu)着不同的規則和(hé)自己的格式,支持着各種安全性的傳輸。
日志(zhì)系統優化思路

有(yǒu)了上(shàng)述日志(zhì)的架構,我們針對各種實際的應用場(chǎng)景,進一步提出了四個(gè)方面的優化思路:
基礎優化
內(nèi)存:如何分配內(nèi)存、垃圾回收、增加緩存和(hé)鎖。
網絡:網絡傳輸序列化、增加壓縮、策略、散列、不同協議與格式。
CPU:用多(duō)線程提高(gāo)利用率和(hé)負載。
此處利用率和(hé)負載是兩個(gè)不同的概念:
利用率:在用滿一個(gè)核後再用下一個(gè)內(nèi)核,利用率是逐步升高(gāo)的。
負載:一下子把八個(gè)核全用上(shàng)了,則負載雖然是滿的,但(dàn)是利用率很(hěn)低(dī)。即,每核都被占用了,但(dàn)是所占用的資源卻不多(duō),計(jì)算(suàn)率比較低(dī)下。
磁盤:嘗試通(tōng)過文件合并,減少(shǎo)碎片文件的産生(shēng),并減少(shǎo)尋道(dào)次數(shù)。同時(shí)在系統級别,通(tōng)過修改設置,關閉各種無用的服務。
平台擴展
做(zuò)加減法,或稱替代方案:無論是互聯網應用,還(hái)是日常應用,我們在查詢時(shí)都增加了分布式緩存,以有(yǒu)效提升查詢的效率。另外,我們将不被平台使用到的地方直接關閉或去除。
縱向擴展:如增加擴展磁盤和(hé)內(nèi)存。
橫向擴展:加減/平行(xíng)擴展,使用分布式集群。
數(shù)據分治
根據數(shù)據的不同維度,對數(shù)據進行(xíng)分類、分級。例如:我們從日志(zhì)中區(qū)分error、info、和(hé) debug,甚至将 info 和(hé) debug 級别的日志(zhì)直接過濾掉。
數(shù)據熱點:例如:某種日志(zhì)數(shù)據在白天的某個(gè)時(shí)間(jiān)段內(nèi)呈現暴漲趨勢,而晚上(shàng)隻是平穩産生(shēng)。我們就可(kě)以根據此熱點情況将它們取出來(lái)單獨處理(lǐ),以打散熱點。
系統降級
我們在對整體(tǐ)業務進行(xíng)有(yǒu)效區(qū)分的基礎上(shàng),通(tōng)過制(zhì)定一些(xiē)降級方案,将部分不重要的功能停掉,以滿足核心業務。
日志(zhì)系統優化實踐
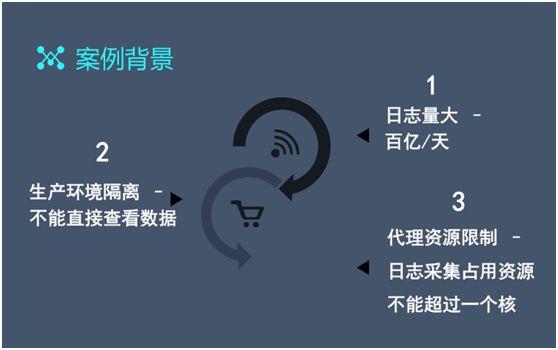
面對持續增長的數(shù)據量,我們雖然增加了許多(duō)資源,但(dàn)是并不能從根本上(shàng)解決問題。
特别體(tǐ)現在如下三方面:
日志(zhì)産生(shēng)量龐大(dà),每天有(yǒu)幾百億條。
由于生(shēng)産環境隔離,我們無法直接查看到數(shù)據。
代理(lǐ)資源限制(zhì),我們的各種日志(zhì)采集和(hé)系統資源采集操作(zuò),不可(kě)超過業務資源的一個(gè)核。
一級業務架構
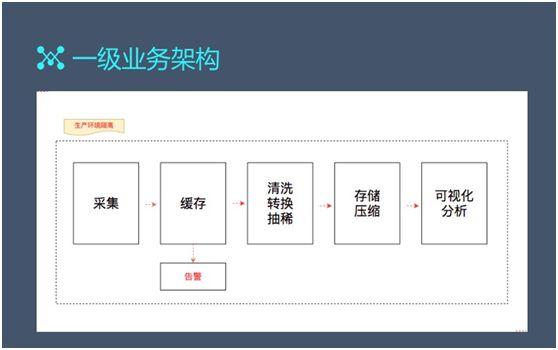
我們日志(zhì)系統的層次相對比較清晰,可(kě)簡單分為(wèi)數(shù)據接入、數(shù)據存儲和(hé)數(shù)據可(kě)視(shì)化三大(dà)塊。
具體(tǐ)包括:
Rsyslog,是目前我們所接觸到的采集工具中最節省性能的一種。
Kafka,具有(yǒu)持久化的作(zuò)用。當然它在使用到達一定數(shù)據量級時(shí),會(huì)出現 Bug。
Fluentd,它與 Rsyslog 類似,也是一種日志(zhì)的傳輸工具,但(dàn)是它更偏向傳輸服務。
ES 和(hé) Kibana。
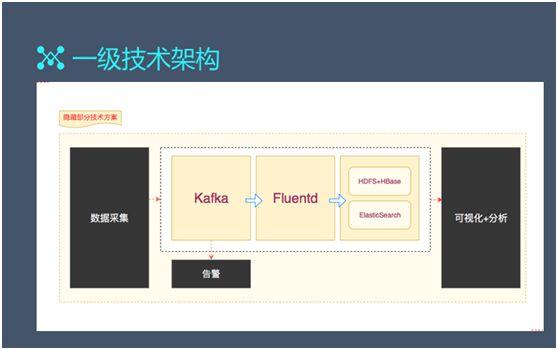
該架構在實現上(shàng)會(huì)用到 Golang、Ruby、Java、JS 等不同的語言。在後期改造時(shí),我們會(huì)将符合 Key-Value 模式的數(shù)據快速地導入 HBase 之中。
基于 HBase 的自身特點,我們實現了它在內(nèi)存層的 B+ 樹(shù),并且持久化到我們的磁盤之上(shàng),從而達到了理(lǐ)想的快速插入的速度。這也正是我們願意選擇 HBase 作(zuò)為(wèi)日志(zhì)方案的原因。
二級業務架構
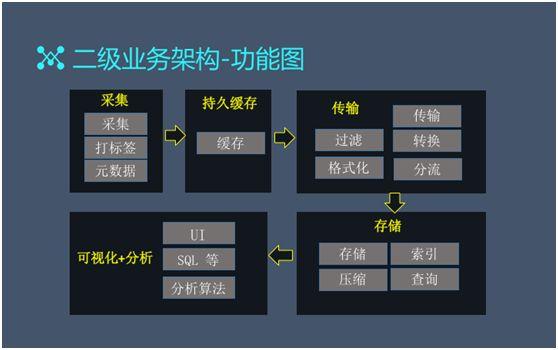
我們直接來(lái)看二級業務架構的功能圖,它是由如下流程串聯而成的:
在完成了數(shù)據采集之後,為(wèi)了節省自己占用磁盤的空(kōng)間(jiān),許多(duō)應用會(huì)完全依賴于我們的日志(zhì)系統。因此在數(shù)據采集完以後,我們增加了一個(gè)持久緩存。
完成緩存之後系統執行(xíng)傳輸。傳輸的過程包括:過濾和(hé)轉換,這個(gè)過程可(kě)以進行(xíng)數(shù)據抽稀。值得(de)強調的是:如果業務方盡早合作(zuò)并給予我們一些(xiē)約定的話(huà),我們就能夠通(tōng)過格式化來(lái)實現結構化的數(shù)據。
随後執行(xíng)的是分流,其主要包括兩大(dà)塊:一種是 A 來(lái)源的數(shù)據走 A 通(tōng)道(dào),B 來(lái)源的數(shù)據走 B 通(tōng)道(dào)。另一種是讓 A 數(shù)據流入到我們的存儲設備,并觸發保護機制(zhì)。即為(wèi)了保障存儲系統,我們額外增加了一個(gè)隊列。
例如:隊列為(wèi) 100,裏面的一個(gè) chunk 為(wèi) 256 兆,我們現在設置高(gāo)水(shuǐ)位為(wèi) 0.7、低(dī)水(shuǐ)位為(wèi) 0.3。
在寫操作(zuò)的堆積時(shí),由于我們設置了 0.7,即 100 兆赫。那(nà)麽在一個(gè) 256 兆會(huì)堆積到 70 個(gè) chunk 時(shí),我們往該存儲平台的寫速度就已經跟不上(shàng)了。
此時(shí)高(gāo)水(shuǐ)位點會(huì)被觸發,不允許繼續寫入,直到整個(gè)寫入過程把該 chunk 消化掉,并降至 30 個(gè)時(shí),方可(kě)繼續往裏寫入。我們就是用該保護機制(zhì)來(lái)保護後台以及存儲設備的。
接着是存儲,由于整個(gè)數(shù)據流的量會(huì)比較大(dà),因此在存儲環節主要執行(xíng)的是存儲的索引、壓縮、和(hé)查詢。
最後是 UI 的一些(xiē)分析算(suàn)法,運用 SQL 的一些(xiē)查詢語句進行(xíng)簡單、快速地查詢。
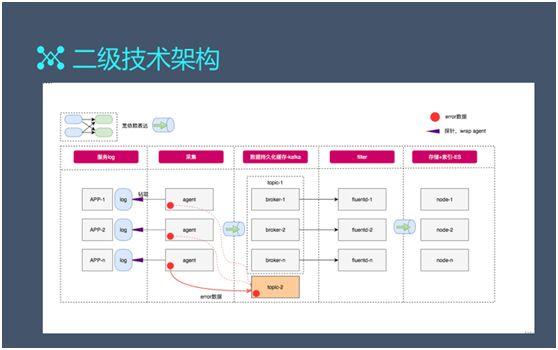
通(tōng)常從采集(logstash/rsyslog/heka/filebeat)到面向緩存的 Kafka 是一種典型的寬依賴。
所謂寬依賴,是指每個(gè) App 都可(kě)能跟每個(gè) Broker 相關聯。在 Kafka 處,每次傳輸都要在哈希之後,再把數(shù)據寫到每個(gè) Broker 上(shàng)。
而窄依賴,則是其每一個(gè) Fluentd 進程都隻對應一個(gè) Broker 的過程。最終通(tōng)過寬依賴過程寫入到 ES。
采集
如 Rsyslog 不但(dàn)占用資源最少(shǎo),而且可(kě)以添加各種規則,它還(hái)能支持像 TSL、SSL 之類的安全協議。
Filebeat 輕量,在版本 5.x 中,Elasticsearch 具有(yǒu)解析的能力(像 Logstash 過濾器(qì))— Ingest。
這也就意味着可(kě)以将數(shù)據直接用 Filebeat 推送到 Elasticsearch,并讓 Elasticsearch 既做(zuò)解析的事情,又做(zuò)存儲的事情。
Kafka
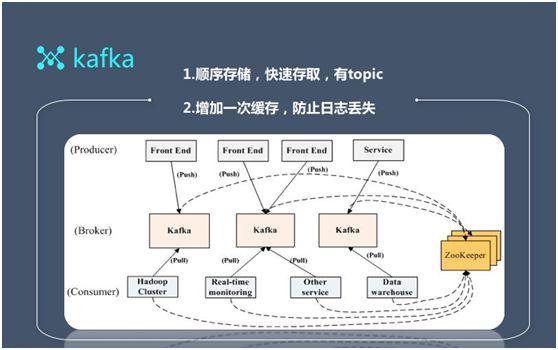
接着是 Kafka,Kafka 主要實現的是順序存儲,它通(tōng)過 topic 和(hé)消息隊列的機制(zhì),實現了快速地數(shù)據存儲。
而它的缺點:由于所有(yǒu)的數(shù)據都向 Kafka 寫入,會(huì)導緻 topic 過多(duō),引發磁盤競争,進而嚴重拖累 Kafka 的性能。
另外,如果所有(yǒu)的數(shù)據都使用統一标簽的話(huà),由于不知道(dào)所采集到的數(shù)據具體(tǐ)類别,我們将很(hěn)難實現對數(shù)據的分治。
因此,在後面的優化傳輸機制(zhì)方面,我們改造并自己實現了順序存儲的過程,進而解決了一定要做(zuò)持久化這一安全保障的需求。
Fluentd
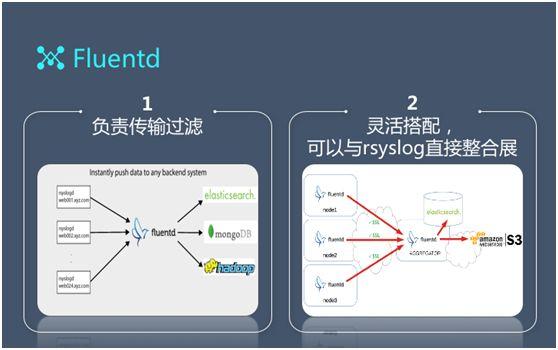
Fluentd 有(yǒu)點類似于 Logstash,它的文檔和(hé)插件非常齊全。其多(duō)種插件可(kě)保證直接對接到 Hadoop 或 ES。
就接入而言,我們可(kě)以采用 Fluentd 到 Fluentd 的方式。即在原有(yǒu)一層數(shù)據接入的基礎上(shàng),再接一次 Fluentd。同時(shí)它也支持安全傳輸。當然我們在後面也對它進行(xíng)了重點優化。
ES+Kibana
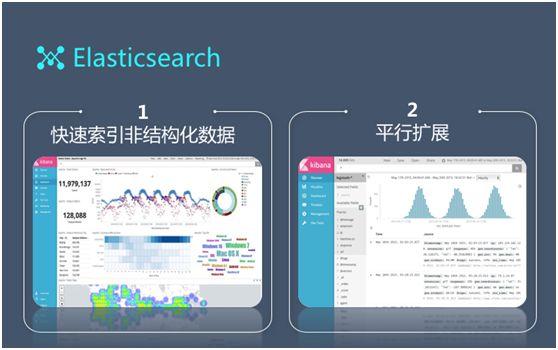
最後我們用到了 ES 和(hé) Kibana。ES 的優勢在于通(tōng)過 Lucene 實現了快速的倒排索引。
由于大(dà)量的日志(zhì)是非結構化的,因此我們使用 ES 的 Lucene 進行(xíng)包裝,以滿足普通(tōng)用戶執行(xíng)非結構化日志(zhì)的搜索。而 Kibana 則基于 Lucene 提供可(kě)視(shì)化顯示工具。
問題定位與解決
下面介紹一下我們碰到過的問題和(hé)現象,如下這些(xiē)都是我們着手優化的出發點:
傳輸服務器(qì)的 CPU 利用率低(dī)下,每個(gè)核的負載不飽滿。
傳輸服務器(qì) Full gc 的頻次過高(gāo)。由于我們是使用 Ruby 來(lái)實現的過程,其內(nèi)存默認設置的數(shù)據量有(yǒu)時(shí)會(huì)過大(dà)。
存儲服務器(qì)出現單波峰現象,即存儲服務器(qì)磁盤有(yǒu)時(shí)會(huì)突然出現性能直線驟升或驟降。
頻繁觸發高(gāo)水(shuǐ)位。如前所述的高(gāo)水(shuǐ)位保護機制(zhì),一旦存儲磁盤觸發了高(gāo)水(shuǐ)位,則不再提供服務,隻能等待人(rén)工進行(xíng)磁盤“清洗”。
如果 ES 的一台機器(qì)“挂”了,則集群就 hang 住了。即當發現某台機器(qì)無法通(tōng)訊時(shí),集群會(huì)認為(wèi)它“挂”了,則快速啓動數(shù)據恢複。而如果正值系統繁忙之時(shí),則此類數(shù)據恢複的操作(zuò)會(huì)更加拖累系統的整體(tǐ)性能。
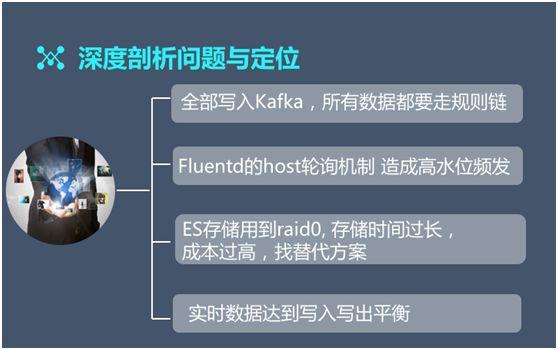
由于所有(yǒu)數(shù)據都被寫入 Kafka,而我們隻用到了一個(gè) topic,這就造成了每一類數(shù)據都要經過不一定與之相關的規則鏈,并進行(xíng)不一定适用的規則判斷,因此數(shù)據的傳輸效率整體(tǐ)被降低(dī)了。
Fluentd 的 host 輪詢機制(zhì)造成高(gāo)水(shuǐ)位頻發。由于 Fluentd 在與 ES 對接時(shí)遵循一個(gè)默認策略:首選前五台進行(xíng)數(shù)據寫入,即與前五台的前五個(gè)接口交互。
在我們的生(shēng)産環境中,Fluentd 是用 CRuby 寫的。每一個(gè)進程屬于一個(gè) Fluentd 進程,且每一個(gè)進程都會(huì)對應一個(gè) host 文件。
而該 host 文件的前五個(gè)默認值即為(wèi) ES 的寫入入口,因此所有(yǒu)機器(qì)都會(huì)去找這五個(gè)入口。
倘若有(yǒu)一台機器(qì)宕機,則會(huì)輪詢到下一台。如此直接造成了高(gāo)水(shuǐ)位的頻繁出現、和(hé)寫入速度的下降。
衆所周知,對日志(zhì)的查詢是一種低(dī)頻次的查詢,即隻有(yǒu)在出現問題時(shí)才會(huì)去查看。但(dàn)是在實際操作(zuò)中,我們往往通(tōng)過檢索的方式全部取出,因此意義不大(dà)。
另外 ES 為(wèi)了達到較好的性能,會(huì)将數(shù)據存儲在 raid0 中,存儲的時(shí)間(jiān)跨度往往會(huì)超過 7 天,因此其成本也比較高(gāo)。
通(tōng)過對數(shù)據的實時(shí)線分析,我們發現并未達到寫入/寫出的平衡狀态。
 為(wèi)了提高(gāo) Fluentd 的利用率,我們用 Kafka 去數(shù)據的時(shí)候提高(gāo)了量,原來(lái)是 5 兆,現在我們改到了 6 兆。
為(wèi)了提高(gāo) Fluentd 的利用率,我們用 Kafka 去數(shù)據的時(shí)候提高(gāo)了量,原來(lái)是 5 兆,現在我們改到了 6 兆。
如果隻是單純傳輸,不論計(jì)算(suàn)的話(huà),其實可(kě)以改更高(gāo)。隻不過因為(wèi)我們考慮到這裏包含了計(jì)算(suàn)的一些(xiē)東西,所以隻提到了 6 兆。
我們的 Fluentd 是基于 JRuby 的,因為(wèi) JRuby 可(kě)以多(duō)線程,但(dàn)是我們的 CRuby 沒有(yǒu)任何意義。
為(wèi)了提高(gāo)內(nèi)存,我把 Ruby 所有(yǒu)的內(nèi)存機制(zhì)了解了一下,就是散列的一些(xiē) host 文件,因為(wèi)我們每個(gè)進程都選前五列就可(kě)以了,我多(duō)開(kāi)了幾個(gè)口。ES 的優化這一塊,在上(shàng) ES 之前,我們已經有(yǒu)人(rén)做(zuò)過一次優化了。
因為(wèi)基于我剛才說的有(yǒu)時(shí)候日志(zhì)量很(hěn)高(gāo),有(yǒu)時(shí)候日志(zhì)量很(hěn)少(shǎo)。我們會(huì)考慮做(zuò)動态配置。
因為(wèi) ES 就是支持動态配置的,所以它動态配置的時(shí)候,我們在某些(xiē)場(chǎng)景下可(kě)以提高(gāo)它的寫入速度,某些(xiē)場(chǎng)景下可(kě)以支持它的這種查詢效率。我們可(kě)以嘗試去做(zuò)一些(xiē)動态配置負載。
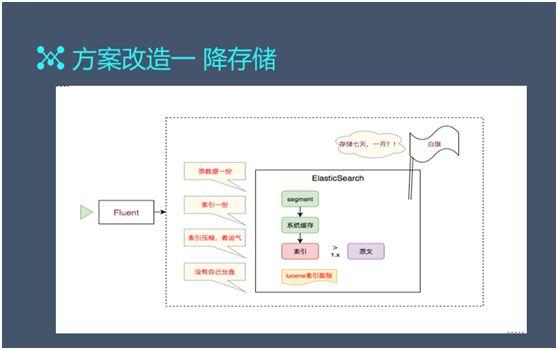
改造一:存儲降低(dī)
降低(dī)存儲在整體(tǐ)架構上(shàng)并沒有(yǒu)太大(dà)變化,我們隻是在傳輸到 Fluentd 時(shí)把天數(shù)降下來(lái),改成了一天。
同時(shí),我們直接進行(xíng)了分流,把數(shù)據往 Hadoop 裏寫,而把一些(xiē)符合 Kibana 的數(shù)據直接放入 ES。
上(shàng)面提過,日志(zhì)查詢是低(dī)頻次的,一般需要查詢兩天以上(shàng)數(shù)據的可(kě)能性很(hěn)小(xiǎo),因此我們降低(dī)存儲是非常有(yǒu)意義的。
改造二:數(shù)據分治

我們在日志(zhì)文件節點數(shù)較少(shǎo)(機器(qì)數(shù)量小(xiǎo)于 5 台)的情況下,去掉了 Kafka 層。由于 Fluentd 可(kě)以支持數(shù)據和(hé)大(dà)文件存儲,因此數(shù)據能夠被持久化地存入磁盤。
我們給每個(gè)應用都直接對應了一個(gè) tag,以方便各個(gè)應用對應到自己的 tag、遵循自己的固定規則、并最終寫入 ES,這樣就方便了出現問題的各自定位。
另外,我們運用延遲計(jì)算(suàn)和(hé)文件切分也能快速地找到問題的根源。因此我們節約了 Kafka 和(hé) ES 各種計(jì)算(suàn)資源。
在實際操作(zuò)中,由于 HBase 不用去做(zuò) raid,它自己完全能夠控制(zhì)磁盤的寫入,因此我們進行(xíng)了數(shù)據壓縮。就其效果而言,ES 的存儲開(kāi)銷大(dà)幅降低(dī)。
在後期,我們也嘗試過一種更為(wèi)極端的方案:讓用戶直接通(tōng)過客戶端的 Shell 去查詢數(shù)據,并采用本地緩存的留存機制(zhì)。
優化效果

優化的效果如下:
服務器(qì)資源的有(yǒu)效利用。在實施了新的方案之後,我們省了很(hěn)多(duō)服務器(qì),而且單台服務器(qì)的存儲資源也節省了 15%。
單核處理(lǐ)每秒(miǎo)原來(lái)能夠傳輸 3000 條,實施後提升到了 1.5~1.8 萬條。而且,在服務器(qì)單獨空(kōng)跑,即不加任何計(jì)算(suàn)時(shí),單核每秒(miǎo)能傳輸近 3 萬條。
很(hěn)少(shǎo)觸發 ES 保護機制(zhì)。原因就是我們已把數(shù)據分流出來(lái)了。
以前曆史數(shù)據隻能存 7 天,由于我們節省了服務器(qì),因此我們現在可(kě)以存儲更長時(shí)間(jiān)的數(shù)據。而且,對于一些(xiē)他人(rén)查詢過的日志(zhì),我們也會(huì)根據最初的策略,有(yǒu)選擇性地保留下來(lái),以便追溯。
日志(zhì)系統優化總結
關于日志(zhì)平台優化,我總結了如下幾點:
由于日志(zhì)是低(dī)頻次的,我們把曆史數(shù)據存入了廉價存儲之中,普通(tōng)用戶需要的時(shí)候,我們再導到 ES 裏,通(tōng)過 Kibana 的前端界面便可(kě)快速查詢到。而對于程序員來(lái)說,則不需要到 ES 便可(kě)直接查詢到。
數(shù)據存在的時(shí)間(jiān)越長,則意義越小(xiǎo)。我們根據實際情況制(zhì)定了有(yǒu)效的、留存有(yǒu)意義數(shù)據的策略。
順序寫盤替代內(nèi)存。例如:區(qū)别于平常的随機寫盤,我們在操作(zuò)讀寫一個(gè)流文件時(shí)采取的是按順序寫數(shù)據的模式。
而在存儲量大(dà)的時(shí)候,則應當考慮 SSD。特别是在 ES 遇到限流時(shí),使用 SSD 可(kě)以提升 ES 的性能。
提前定制(zhì)規範,從而能夠有(yǒu)效解決後期分析等工作(zuò)。
日志(zhì)格式
如上(shàng)圖所示,常用的日志(zhì)格式類型包括:uuid、timestamp、host 等。
特别是 host,由于日志(zhì)會(huì)涉及到幾百個(gè)節點,有(yǒu)了 host 類型,我們就能判定是哪台機器(qì)上(shàng)的标準。而圖中其他的環境變量類型,則能夠有(yǒu)效地追溯到一些(xiē)曆史的信息。
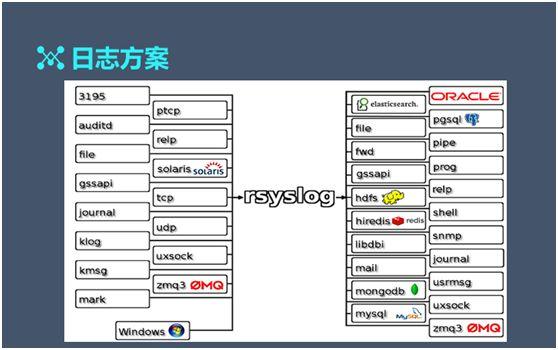
日志(zhì)方案
如上(shàng)圖所示,我們通(tōng)過 Rsyslog 可(kě)以直接将采集端的數(shù)據寫入文件或數(shù)據庫之中。
當然,對于一些(xiē)暫時(shí)用不上(shàng)的日志(zhì),我們不一定非要實施過濾傳輸的規則。
如上(shàng)圖,Fluentd 也有(yǒu)一些(xiē)傳輸的規則,包括:Fluentd 可(kě)以直接對接 Fluentd,也可(kě)以直接對接 MongoDB、MySQL 等。
另外,我們也有(yǒu)一些(xiē)組件可(kě)以快速地對接插件和(hé)系統,例如讓 Fluentd 和(hé) Rsyslog 能夠直接連到 ES 上(shàng)。
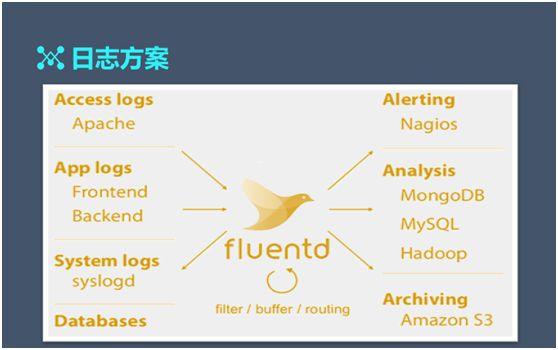
這是我個(gè)人(rén)給大(dà)家(jiā)定制(zhì)的一些(xiē)最基本的基線,我認為(wèi)日志(zhì)從采集、緩存、傳輸、存儲,到最終可(kě)視(shì)化,分成了三套基線。
采集到存儲是最簡單的一個(gè),像 Rsyslog 到 hdfs 或者其他 filesystem,我們有(yǒu)這種情況。
比較常見的情況,就是從采集、傳輸、到存儲可(kě)視(shì)化,然後形成最終我們現在最複雜的一套系統,大(dà)家(jiā)可(kě)以根據實際情況取舍。
最後是我考慮到一個(gè)實際情況,假如這個(gè)案例,我們盡可(kě)能少(shǎo)的占有(yǒu)服務器(qì),然後傳輸需要過濾轉換,日志(zhì)可(kě)以比較簡單,符合這種 Key value(KV)格式。
我們可(kě)以按照取了一個(gè) Rsyslog、取了一個(gè) Fluentd、取了一個(gè) Hbase,取了一個(gè) echars 等這麽一個(gè)方式做(zuò)一個(gè)方案就可(kě)以了。
我覺得(de) Rsyslog、Fluentd、heka 這些(xiē)都可(kě)以做(zuò)采集。然後傳輸這塊有(yǒu) Fluentd 傳輸,因為(wèi) Fluentd 和(hé) Kafka 到插件非常靈活可(kě)以直接對接我們很(hěn)多(duō)存儲設備,也可(kě)以對應很(hěn)多(duō)的文件、連 ES 都可(kě)以。
可(kě)視(shì)化可(kě)以用 Kibana,主要是跟 ES 結合得(de)比較緊密,它們結合在一起需要一點學習成本。
關于作(zuò)者
楊津萍,大(dà)數(shù)據架構師(shī),從業十餘年,專攻 Web 架構及大(dà)數(shù)據架構。開(kāi)源的熱衷人(rén)員,對大(dà)數(shù)據類項目,如 Hadoop、Hive、Shark 等,有(yǒu)過開(kāi)源貢獻。 目前在凡普金科擔任大(dà)數(shù)據架構師(shī)職位。
本文将從海量日志(zhì)系統在優化、部署、監控方向如何更适應業務的需求入手,重點從多(duō)種日志(zhì)系統的架構設計(jì)對比;後續調優過程:橫向擴展與縱向擴展,分集群,數(shù)據分治,重寫數(shù)據鏈路等實際現象與問題展開(kāi)。
日志(zhì)系統架構基準
有(yǒu)過項目開(kāi)發經驗的朋友(yǒu)都知道(dào):從平台的最初搭建到實現核心業務,都需要有(yǒu)日志(zhì)平台為(wèi)各種業務保駕護航。
随着業務複雜度的增加,應用場(chǎng)景也會(huì)變得(de)複雜。雖然監控系統能夠顯示某台機器(qì)或者某個(gè)應用的錯誤。
然而在實際的生(shēng)産環境中,由于實施了隔離,一旦在上(shàng)圖下側的紅框內(nèi)某個(gè)應用出現了 Bug,則無法訪問到其對應的日志(zhì),也就談不上(shàng)将日志(zhì)取出了。
另外,有(yǒu)些(xiē)深度依賴日志(zhì)平台的應用,也可(kě)能在日志(zhì)産生(shēng)的時(shí)候就直接采集走,進而删除掉原始的日志(zhì)文件。這些(xiē)場(chǎng)景給我們日志(zhì)系統的維護都帶來(lái)了難度。
參考 Logstash,一般會(huì)有(yǒu)兩種日志(zhì)業務流程:
正常情況下的簡單流程為(wèi):應用産生(shēng)日志(zhì)→根據預定義的日志(zhì)文件大(dà)小(xiǎo)或時(shí)間(jiān)間(jiān)隔,通(tōng)過執行(xíng) Logrotation,不斷刷新出新的文件→定期查看→定期删除。
複雜應用場(chǎng)景的流程為(wèi):應用産生(shēng)日志(zhì)→采集→傳輸→按需過濾與轉換→存儲→分析與查看。
我們可(kě)以從實時(shí)性和(hé)錯誤分析兩個(gè)維度來(lái)區(qū)分不同的日志(zhì)數(shù)據場(chǎng)景:
實時(shí),一般适用于我們常說的一級應用,如:直接面向用戶的應用。我們可(kě)以自定義各類關鍵字,以方便在出現各種 error 或 exception 時(shí),相關業務人(rén)員能夠在第一時(shí)間(jiān)被通(tōng)知到。
準實時(shí),一般适用于一些(xiē)項目管理(lǐ)的平台,如:在需要填寫工時(shí)的時(shí)候出現了宕機,但(dàn)這并不影(yǐng)響工資的發放。
平台在幾分鍾後完成重啓,我們可(kě)以再登錄填寫,該情況并不造成原則性的影(yǐng)響。因此,我們可(kě)以将其列為(wèi)準實時(shí)的級别。
除了直接采集錯誤與異常,我們還(hái)需要進行(xíng)分析。例如:僅知道(dào)某人(rén)的體(tǐ)重是沒什麽意義的,但(dàn)是如果增加了性别和(hé)身高(gāo)兩個(gè)指标,那(nà)麽我們就可(kě)以判斷出此人(rén)的體(tǐ)重是否為(wèi)标準體(tǐ)重。
也就是說:如果能給出多(duō)個(gè)指标,就可(kě)以對龐大(dà)的數(shù)據進行(xíng)去噪,然後通(tōng)過回歸分析,讓采集到的數(shù)據更有(yǒu)意義。
此外,我們還(hái)要不斷地去還(hái)原數(shù)字的真實性。特别是對于實時(shí)的一級應用,我們要能快速地讓用戶明(míng)白他們所碰到現象的真實含義。
例如:商家(jiā)在上(shàng)架時(shí)錯把商品的價格标簽 100 元标成了 10 元。這會(huì)導緻商品馬上(shàng)被搶購一空(kōng)。
但(dàn)是這種現象并非是業務的問題,很(hěn)難被發現,因此我們隻能通(tōng)過日志(zhì)數(shù)據進行(xíng)邏輯分析,及時(shí)反饋以保證在幾十秒(miǎo)之後将庫存修改為(wèi)零,從而有(yǒu)效地解決此問題。可(kě)見,在此應用場(chǎng)景中,實時(shí)分析就顯得(de)非常有(yǒu)用。
最後是追溯,我們需要在獲取曆史信息的同時(shí),實現跨時(shí)間(jiān)維度的對比與總結,那(nà)麽追溯就能夠在各種應用中發揮其關聯性作(zuò)用了。
上(shàng)述提及的各個(gè)要素都是我們管理(lǐ)日志(zhì)的基準。如上(shàng)圖所示,我們的日志(zhì)系統采用的是開(kāi)源的 ELK 模式:
ElasticSearch(後簡稱 ES),負責後端集中存儲與查詢工作(zuò)。
單獨的 Beats 負責日志(zhì)的搜集。FileBeat 則改進了 Logstash 的資源占用問題;TopBeat 負責搜集監控資源,類似系統命令 top 去獲取 CPU 的性能。
由于日志(zhì)服務對于業務來(lái)說僅起到了維穩和(hé)保障的作(zuò)用,而且我們需要實現快速、輕量的數(shù)據采集與傳輸,因此不應占用服務器(qì)太多(duō)資源。
在方式上(shàng)我們采用的是插件模式,包括:input 插件、output 插件、以及中間(jiān)負責傳輸過濾的插件。這些(xiē)插件有(yǒu)着不同的規則和(hé)自己的格式,支持着各種安全性的傳輸。
日志(zhì)系統優化思路
有(yǒu)了上(shàng)述日志(zhì)的架構,我們針對各種實際的應用場(chǎng)景,進一步提出了四個(gè)方面的優化思路:
基礎優化
內(nèi)存:如何分配內(nèi)存、垃圾回收、增加緩存和(hé)鎖。
網絡:網絡傳輸序列化、增加壓縮、策略、散列、不同協議與格式。
CPU:用多(duō)線程提高(gāo)利用率和(hé)負載。
此處利用率和(hé)負載是兩個(gè)不同的概念:
利用率:在用滿一個(gè)核後再用下一個(gè)內(nèi)核,利用率是逐步升高(gāo)的。
負載:一下子把八個(gè)核全用上(shàng)了,則負載雖然是滿的,但(dàn)是利用率很(hěn)低(dī)。即,每核都被占用了,但(dàn)是所占用的資源卻不多(duō),計(jì)算(suàn)率比較低(dī)下。
磁盤:嘗試通(tōng)過文件合并,減少(shǎo)碎片文件的産生(shēng),并減少(shǎo)尋道(dào)次數(shù)。同時(shí)在系統級别,通(tōng)過修改設置,關閉各種無用的服務。
平台擴展
做(zuò)加減法,或稱替代方案:無論是互聯網應用,還(hái)是日常應用,我們在查詢時(shí)都增加了分布式緩存,以有(yǒu)效提升查詢的效率。另外,我們将不被平台使用到的地方直接關閉或去除。
縱向擴展:如增加擴展磁盤和(hé)內(nèi)存。
橫向擴展:加減/平行(xíng)擴展,使用分布式集群。
數(shù)據分治
根據數(shù)據的不同維度,對數(shù)據進行(xíng)分類、分級。例如:我們從日志(zhì)中區(qū)分error、info、和(hé) debug,甚至将 info 和(hé) debug 級别的日志(zhì)直接過濾掉。
數(shù)據熱點:例如:某種日志(zhì)數(shù)據在白天的某個(gè)時(shí)間(jiān)段內(nèi)呈現暴漲趨勢,而晚上(shàng)隻是平穩産生(shēng)。我們就可(kě)以根據此熱點情況将它們取出來(lái)單獨處理(lǐ),以打散熱點。
系統降級
我們在對整體(tǐ)業務進行(xíng)有(yǒu)效區(qū)分的基礎上(shàng),通(tōng)過制(zhì)定一些(xiē)降級方案,将部分不重要的功能停掉,以滿足核心業務。
日志(zhì)系統優化實踐
面對持續增長的數(shù)據量,我們雖然增加了許多(duō)資源,但(dàn)是并不能從根本上(shàng)解決問題。
特别體(tǐ)現在如下三方面:
日志(zhì)産生(shēng)量龐大(dà),每天有(yǒu)幾百億條。
由于生(shēng)産環境隔離,我們無法直接查看到數(shù)據。
代理(lǐ)資源限制(zhì),我們的各種日志(zhì)采集和(hé)系統資源采集操作(zuò),不可(kě)超過業務資源的一個(gè)核。
一級業務架構
我們日志(zhì)系統的層次相對比較清晰,可(kě)簡單分為(wèi)數(shù)據接入、數(shù)據存儲和(hé)數(shù)據可(kě)視(shì)化三大(dà)塊。
具體(tǐ)包括:
Rsyslog,是目前我們所接觸到的采集工具中最節省性能的一種。
Kafka,具有(yǒu)持久化的作(zuò)用。當然它在使用到達一定數(shù)據量級時(shí),會(huì)出現 Bug。
Fluentd,它與 Rsyslog 類似,也是一種日志(zhì)的傳輸工具,但(dàn)是它更偏向傳輸服務。
ES 和(hé) Kibana。
該架構在實現上(shàng)會(huì)用到 Golang、Ruby、Java、JS 等不同的語言。在後期改造時(shí),我們會(huì)将符合 Key-Value 模式的數(shù)據快速地導入 HBase 之中。
基于 HBase 的自身特點,我們實現了它在內(nèi)存層的 B+ 樹(shù),并且持久化到我們的磁盤之上(shàng),從而達到了理(lǐ)想的快速插入的速度。這也正是我們願意選擇 HBase 作(zuò)為(wèi)日志(zhì)方案的原因。
二級業務架構
我們直接來(lái)看二級業務架構的功能圖,它是由如下流程串聯而成的:
在完成了數(shù)據采集之後,為(wèi)了節省自己占用磁盤的空(kōng)間(jiān),許多(duō)應用會(huì)完全依賴于我們的日志(zhì)系統。因此在數(shù)據采集完以後,我們增加了一個(gè)持久緩存。
完成緩存之後系統執行(xíng)傳輸。傳輸的過程包括:過濾和(hé)轉換,這個(gè)過程可(kě)以進行(xíng)數(shù)據抽稀。值得(de)強調的是:如果業務方盡早合作(zuò)并給予我們一些(xiē)約定的話(huà),我們就能夠通(tōng)過格式化來(lái)實現結構化的數(shù)據。
随後執行(xíng)的是分流,其主要包括兩大(dà)塊:一種是 A 來(lái)源的數(shù)據走 A 通(tōng)道(dào),B 來(lái)源的數(shù)據走 B 通(tōng)道(dào)。另一種是讓 A 數(shù)據流入到我們的存儲設備,并觸發保護機制(zhì)。即為(wèi)了保障存儲系統,我們額外增加了一個(gè)隊列。
例如:隊列為(wèi) 100,裏面的一個(gè) chunk 為(wèi) 256 兆,我們現在設置高(gāo)水(shuǐ)位為(wèi) 0.7、低(dī)水(shuǐ)位為(wèi) 0.3。
在寫操作(zuò)的堆積時(shí),由于我們設置了 0.7,即 100 兆赫。那(nà)麽在一個(gè) 256 兆會(huì)堆積到 70 個(gè) chunk 時(shí),我們往該存儲平台的寫速度就已經跟不上(shàng)了。
此時(shí)高(gāo)水(shuǐ)位點會(huì)被觸發,不允許繼續寫入,直到整個(gè)寫入過程把該 chunk 消化掉,并降至 30 個(gè)時(shí),方可(kě)繼續往裏寫入。我們就是用該保護機制(zhì)來(lái)保護後台以及存儲設備的。
接着是存儲,由于整個(gè)數(shù)據流的量會(huì)比較大(dà),因此在存儲環節主要執行(xíng)的是存儲的索引、壓縮、和(hé)查詢。
最後是 UI 的一些(xiē)分析算(suàn)法,運用 SQL 的一些(xiē)查詢語句進行(xíng)簡單、快速地查詢。
通(tōng)常從采集(logstash/rsyslog/heka/filebeat)到面向緩存的 Kafka 是一種典型的寬依賴。
所謂寬依賴,是指每個(gè) App 都可(kě)能跟每個(gè) Broker 相關聯。在 Kafka 處,每次傳輸都要在哈希之後,再把數(shù)據寫到每個(gè) Broker 上(shàng)。
而窄依賴,則是其每一個(gè) Fluentd 進程都隻對應一個(gè) Broker 的過程。最終通(tōng)過寬依賴過程寫入到 ES。
采集
如 Rsyslog 不但(dàn)占用資源最少(shǎo),而且可(kě)以添加各種規則,它還(hái)能支持像 TSL、SSL 之類的安全協議。
Filebeat 輕量,在版本 5.x 中,Elasticsearch 具有(yǒu)解析的能力(像 Logstash 過濾器(qì))— Ingest。
這也就意味着可(kě)以将數(shù)據直接用 Filebeat 推送到 Elasticsearch,并讓 Elasticsearch 既做(zuò)解析的事情,又做(zuò)存儲的事情。
Kafka
接着是 Kafka,Kafka 主要實現的是順序存儲,它通(tōng)過 topic 和(hé)消息隊列的機制(zhì),實現了快速地數(shù)據存儲。
而它的缺點:由于所有(yǒu)的數(shù)據都向 Kafka 寫入,會(huì)導緻 topic 過多(duō),引發磁盤競争,進而嚴重拖累 Kafka 的性能。
另外,如果所有(yǒu)的數(shù)據都使用統一标簽的話(huà),由于不知道(dào)所采集到的數(shù)據具體(tǐ)類别,我們将很(hěn)難實現對數(shù)據的分治。
因此,在後面的優化傳輸機制(zhì)方面,我們改造并自己實現了順序存儲的過程,進而解決了一定要做(zuò)持久化這一安全保障的需求。
Fluentd
Fluentd 有(yǒu)點類似于 Logstash,它的文檔和(hé)插件非常齊全。其多(duō)種插件可(kě)保證直接對接到 Hadoop 或 ES。
就接入而言,我們可(kě)以采用 Fluentd 到 Fluentd 的方式。即在原有(yǒu)一層數(shù)據接入的基礎上(shàng),再接一次 Fluentd。同時(shí)它也支持安全傳輸。當然我們在後面也對它進行(xíng)了重點優化。
ES+Kibana
最後我們用到了 ES 和(hé) Kibana。ES 的優勢在于通(tōng)過 Lucene 實現了快速的倒排索引。
由于大(dà)量的日志(zhì)是非結構化的,因此我們使用 ES 的 Lucene 進行(xíng)包裝,以滿足普通(tōng)用戶執行(xíng)非結構化日志(zhì)的搜索。而 Kibana 則基于 Lucene 提供可(kě)視(shì)化顯示工具。
問題定位與解決
下面介紹一下我們碰到過的問題和(hé)現象,如下這些(xiē)都是我們着手優化的出發點:
傳輸服務器(qì)的 CPU 利用率低(dī)下,每個(gè)核的負載不飽滿。
傳輸服務器(qì) Full gc 的頻次過高(gāo)。由于我們是使用 Ruby 來(lái)實現的過程,其內(nèi)存默認設置的數(shù)據量有(yǒu)時(shí)會(huì)過大(dà)。
存儲服務器(qì)出現單波峰現象,即存儲服務器(qì)磁盤有(yǒu)時(shí)會(huì)突然出現性能直線驟升或驟降。
頻繁觸發高(gāo)水(shuǐ)位。如前所述的高(gāo)水(shuǐ)位保護機制(zhì),一旦存儲磁盤觸發了高(gāo)水(shuǐ)位,則不再提供服務,隻能等待人(rén)工進行(xíng)磁盤“清洗”。
如果 ES 的一台機器(qì)“挂”了,則集群就 hang 住了。即當發現某台機器(qì)無法通(tōng)訊時(shí),集群會(huì)認為(wèi)它“挂”了,則快速啓動數(shù)據恢複。而如果正值系統繁忙之時(shí),則此類數(shù)據恢複的操作(zuò)會(huì)更加拖累系統的整體(tǐ)性能。
由于所有(yǒu)數(shù)據都被寫入 Kafka,而我們隻用到了一個(gè) topic,這就造成了每一類數(shù)據都要經過不一定與之相關的規則鏈,并進行(xíng)不一定适用的規則判斷,因此數(shù)據的傳輸效率整體(tǐ)被降低(dī)了。
Fluentd 的 host 輪詢機制(zhì)造成高(gāo)水(shuǐ)位頻發。由于 Fluentd 在與 ES 對接時(shí)遵循一個(gè)默認策略:首選前五台進行(xíng)數(shù)據寫入,即與前五台的前五個(gè)接口交互。
在我們的生(shēng)産環境中,Fluentd 是用 CRuby 寫的。每一個(gè)進程屬于一個(gè) Fluentd 進程,且每一個(gè)進程都會(huì)對應一個(gè) host 文件。
而該 host 文件的前五個(gè)默認值即為(wèi) ES 的寫入入口,因此所有(yǒu)機器(qì)都會(huì)去找這五個(gè)入口。
倘若有(yǒu)一台機器(qì)宕機,則會(huì)輪詢到下一台。如此直接造成了高(gāo)水(shuǐ)位的頻繁出現、和(hé)寫入速度的下降。
衆所周知,對日志(zhì)的查詢是一種低(dī)頻次的查詢,即隻有(yǒu)在出現問題時(shí)才會(huì)去查看。但(dàn)是在實際操作(zuò)中,我們往往通(tōng)過檢索的方式全部取出,因此意義不大(dà)。
另外 ES 為(wèi)了達到較好的性能,會(huì)将數(shù)據存儲在 raid0 中,存儲的時(shí)間(jiān)跨度往往會(huì)超過 7 天,因此其成本也比較高(gāo)。
通(tōng)過對數(shù)據的實時(shí)線分析,我們發現并未達到寫入/寫出的平衡狀态。
如果隻是單純傳輸,不論計(jì)算(suàn)的話(huà),其實可(kě)以改更高(gāo)。隻不過因為(wèi)我們考慮到這裏包含了計(jì)算(suàn)的一些(xiē)東西,所以隻提到了 6 兆。
我們的 Fluentd 是基于 JRuby 的,因為(wèi) JRuby 可(kě)以多(duō)線程,但(dàn)是我們的 CRuby 沒有(yǒu)任何意義。
為(wèi)了提高(gāo)內(nèi)存,我把 Ruby 所有(yǒu)的內(nèi)存機制(zhì)了解了一下,就是散列的一些(xiē) host 文件,因為(wèi)我們每個(gè)進程都選前五列就可(kě)以了,我多(duō)開(kāi)了幾個(gè)口。ES 的優化這一塊,在上(shàng) ES 之前,我們已經有(yǒu)人(rén)做(zuò)過一次優化了。
因為(wèi)基于我剛才說的有(yǒu)時(shí)候日志(zhì)量很(hěn)高(gāo),有(yǒu)時(shí)候日志(zhì)量很(hěn)少(shǎo)。我們會(huì)考慮做(zuò)動态配置。
因為(wèi) ES 就是支持動态配置的,所以它動态配置的時(shí)候,我們在某些(xiē)場(chǎng)景下可(kě)以提高(gāo)它的寫入速度,某些(xiē)場(chǎng)景下可(kě)以支持它的這種查詢效率。我們可(kě)以嘗試去做(zuò)一些(xiē)動态配置負載。
改造一:存儲降低(dī)
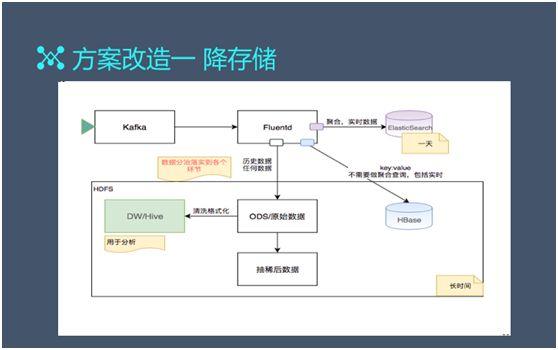
降低(dī)存儲在整體(tǐ)架構上(shàng)并沒有(yǒu)太大(dà)變化,我們隻是在傳輸到 Fluentd 時(shí)把天數(shù)降下來(lái),改成了一天。
同時(shí),我們直接進行(xíng)了分流,把數(shù)據往 Hadoop 裏寫,而把一些(xiē)符合 Kibana 的數(shù)據直接放入 ES。
上(shàng)面提過,日志(zhì)查詢是低(dī)頻次的,一般需要查詢兩天以上(shàng)數(shù)據的可(kě)能性很(hěn)小(xiǎo),因此我們降低(dī)存儲是非常有(yǒu)意義的。
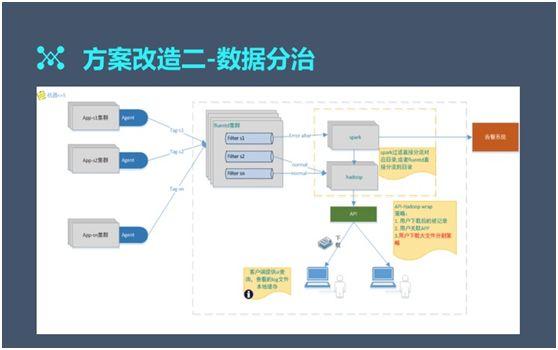
改造二:數(shù)據分治
我們在日志(zhì)文件節點數(shù)較少(shǎo)(機器(qì)數(shù)量小(xiǎo)于 5 台)的情況下,去掉了 Kafka 層。由于 Fluentd 可(kě)以支持數(shù)據和(hé)大(dà)文件存儲,因此數(shù)據能夠被持久化地存入磁盤。
我們給每個(gè)應用都直接對應了一個(gè) tag,以方便各個(gè)應用對應到自己的 tag、遵循自己的固定規則、并最終寫入 ES,這樣就方便了出現問題的各自定位。
另外,我們運用延遲計(jì)算(suàn)和(hé)文件切分也能快速地找到問題的根源。因此我們節約了 Kafka 和(hé) ES 各種計(jì)算(suàn)資源。
在實際操作(zuò)中,由于 HBase 不用去做(zuò) raid,它自己完全能夠控制(zhì)磁盤的寫入,因此我們進行(xíng)了數(shù)據壓縮。就其效果而言,ES 的存儲開(kāi)銷大(dà)幅降低(dī)。
在後期,我們也嘗試過一種更為(wèi)極端的方案:讓用戶直接通(tōng)過客戶端的 Shell 去查詢數(shù)據,并采用本地緩存的留存機制(zhì)。
優化效果
優化的效果如下:
服務器(qì)資源的有(yǒu)效利用。在實施了新的方案之後,我們省了很(hěn)多(duō)服務器(qì),而且單台服務器(qì)的存儲資源也節省了 15%。
單核處理(lǐ)每秒(miǎo)原來(lái)能夠傳輸 3000 條,實施後提升到了 1.5~1.8 萬條。而且,在服務器(qì)單獨空(kōng)跑,即不加任何計(jì)算(suàn)時(shí),單核每秒(miǎo)能傳輸近 3 萬條。
很(hěn)少(shǎo)觸發 ES 保護機制(zhì)。原因就是我們已把數(shù)據分流出來(lái)了。
以前曆史數(shù)據隻能存 7 天,由于我們節省了服務器(qì),因此我們現在可(kě)以存儲更長時(shí)間(jiān)的數(shù)據。而且,對于一些(xiē)他人(rén)查詢過的日志(zhì),我們也會(huì)根據最初的策略,有(yǒu)選擇性地保留下來(lái),以便追溯。
日志(zhì)系統優化總結
關于日志(zhì)平台優化,我總結了如下幾點:
由于日志(zhì)是低(dī)頻次的,我們把曆史數(shù)據存入了廉價存儲之中,普通(tōng)用戶需要的時(shí)候,我們再導到 ES 裏,通(tōng)過 Kibana 的前端界面便可(kě)快速查詢到。而對于程序員來(lái)說,則不需要到 ES 便可(kě)直接查詢到。
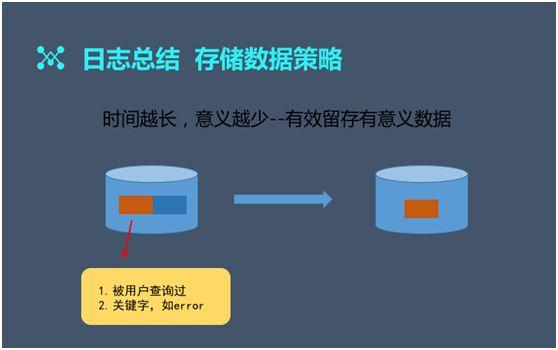
數(shù)據存在的時(shí)間(jiān)越長,則意義越小(xiǎo)。我們根據實際情況制(zhì)定了有(yǒu)效的、留存有(yǒu)意義數(shù)據的策略。
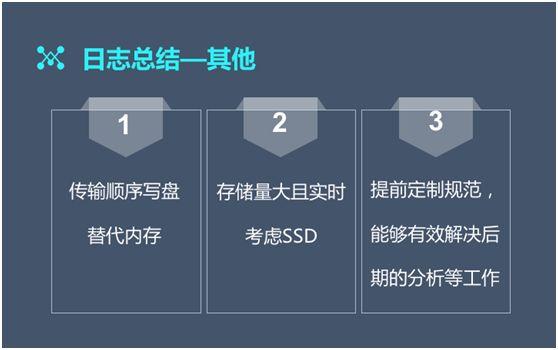
順序寫盤替代內(nèi)存。例如:區(qū)别于平常的随機寫盤,我們在操作(zuò)讀寫一個(gè)流文件時(shí)采取的是按順序寫數(shù)據的模式。
而在存儲量大(dà)的時(shí)候,則應當考慮 SSD。特别是在 ES 遇到限流時(shí),使用 SSD 可(kě)以提升 ES 的性能。
提前定制(zhì)規範,從而能夠有(yǒu)效解決後期分析等工作(zuò)。
日志(zhì)格式
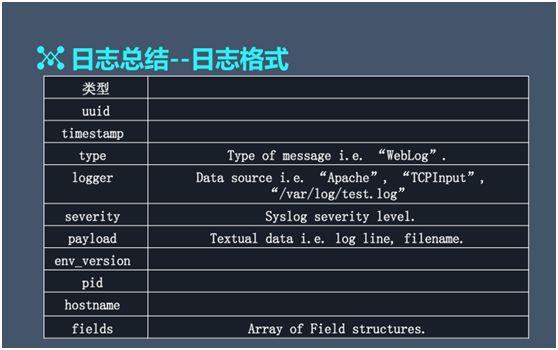
如上(shàng)圖所示,常用的日志(zhì)格式類型包括:uuid、timestamp、host 等。
特别是 host,由于日志(zhì)會(huì)涉及到幾百個(gè)節點,有(yǒu)了 host 類型,我們就能判定是哪台機器(qì)上(shàng)的标準。而圖中其他的環境變量類型,則能夠有(yǒu)效地追溯到一些(xiē)曆史的信息。
日志(zhì)方案
如上(shàng)圖所示,我們通(tōng)過 Rsyslog 可(kě)以直接将采集端的數(shù)據寫入文件或數(shù)據庫之中。
當然,對于一些(xiē)暫時(shí)用不上(shàng)的日志(zhì),我們不一定非要實施過濾傳輸的規則。
如上(shàng)圖,Fluentd 也有(yǒu)一些(xiē)傳輸的規則,包括:Fluentd 可(kě)以直接對接 Fluentd,也可(kě)以直接對接 MongoDB、MySQL 等。
另外,我們也有(yǒu)一些(xiē)組件可(kě)以快速地對接插件和(hé)系統,例如讓 Fluentd 和(hé) Rsyslog 能夠直接連到 ES 上(shàng)。
這是我個(gè)人(rén)給大(dà)家(jiā)定制(zhì)的一些(xiē)最基本的基線,我認為(wèi)日志(zhì)從采集、緩存、傳輸、存儲,到最終可(kě)視(shì)化,分成了三套基線。
采集到存儲是最簡單的一個(gè),像 Rsyslog 到 hdfs 或者其他 filesystem,我們有(yǒu)這種情況。
比較常見的情況,就是從采集、傳輸、到存儲可(kě)視(shì)化,然後形成最終我們現在最複雜的一套系統,大(dà)家(jiā)可(kě)以根據實際情況取舍。
最後是我考慮到一個(gè)實際情況,假如這個(gè)案例,我們盡可(kě)能少(shǎo)的占有(yǒu)服務器(qì),然後傳輸需要過濾轉換,日志(zhì)可(kě)以比較簡單,符合這種 Key value(KV)格式。
我們可(kě)以按照取了一個(gè) Rsyslog、取了一個(gè) Fluentd、取了一個(gè) Hbase,取了一個(gè) echars 等這麽一個(gè)方式做(zuò)一個(gè)方案就可(kě)以了。
我覺得(de) Rsyslog、Fluentd、heka 這些(xiē)都可(kě)以做(zuò)采集。然後傳輸這塊有(yǒu) Fluentd 傳輸,因為(wèi) Fluentd 和(hé) Kafka 到插件非常靈活可(kě)以直接對接我們很(hěn)多(duō)存儲設備,也可(kě)以對應很(hěn)多(duō)的文件、連 ES 都可(kě)以。
可(kě)視(shì)化可(kě)以用 Kibana,主要是跟 ES 結合得(de)比較緊密,它們結合在一起需要一點學習成本。
關于作(zuò)者
楊津萍,大(dà)數(shù)據架構師(shī),從業十餘年,專攻 Web 架構及大(dà)數(shù)據架構。開(kāi)源的熱衷人(rén)員,對大(dà)數(shù)據類項目,如 Hadoop、Hive、Shark 等,有(yǒu)過開(kāi)源貢獻。 目前在凡普金科擔任大(dà)數(shù)據架構師(shī)職位。
聯系我們
一切良好工作(zuò)的開(kāi)始,都需相互之間(jiān)的溝通(tōng)搭橋,歡迎咨詢。



